引:为什么要学 DDGI?
如果说 ReSTIR 是”沿路径维度做重要性重采样”的代表,那 DDGI 就是”沿空间维度做光场缓存”的代表——它走的是一条完全不同的工程路径。
漫反射 GI 的本质特征:低频、空间相关性强、在合理网格密度下采样无明显走样。这意味着我们不需要为每个像素独立追踪光线——把场景中放置一组光照探针,每个探针缓存”全方向的入射辐照度”,着色时插值即可。
但传统的”光照探针 (Light Probe)”方案有三个致命缺陷,DDGI 都给出了优雅的解决方案:
| 传统方案痛点 |
DDGI 的应对 |
| 离线烘焙耗时数小时,不支持动态光源 |
用硬件光追逐帧增量更新探针 |
| 探针穿墙导致漏光(light leaking) |
引入切比雪夫不等式计算可见性权重 |
| Cubemap/SH 存储格式压缩 GI 高频损失大 |
改用八面体映射 + 2D 纹理图集 |
DDGI 已经被部署在多款产品中:
- Unity HDRP 的 APV (Adaptive Probe Volumes) 借鉴了 DDGI 思想
- Unreal Lumen 的 Surface Cache 与 DDGI 互补
- NVIDIA RTXGI-DDGI 是工业级 SDK,被《光环:无限》《艾尔登法环》等游戏使用
- 《Cyberpunk 2077》Path Tracing Mode 之外的 GI 由 DDGI 衍生方案承担
一、核心思想:用探针缓存”全方向的入射光”
1.1 漫反射出射的数学
漫反射表面的渲染方程:
其中 是 albedo, 是各方向的入射辐射度。如果我们能在 处预积分出量 (即”按法线 投影的辐照度”),shading 时一次纹理采样就够。
但这个量是 5 维的(位置 3D + 法线 2D),完全存不下。DDGI 的关键近似:
其中 是 周围 8 个网格探针, 是探针 沿法线 的辐照度, 是权重(包含三线性 + 可见性 + 法线相似度)。
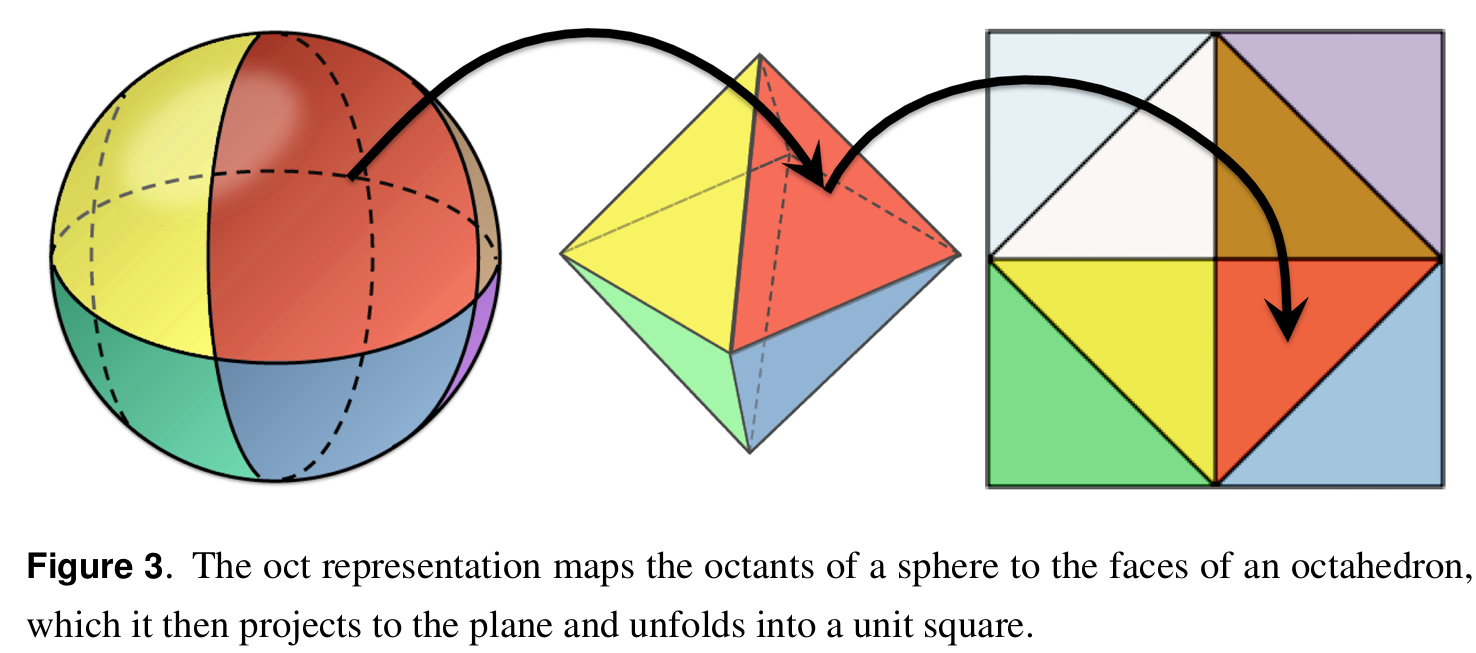
把”位置维度”用网格离散化,”方向维度”用八面体贴图离散化——5D 问题降到了 GPU 友好的 2D 纹理寻址。
1.2 DDGI 数据结构总览
DDGI 的存储分为三个层次:3D 探针网格 → 单探针八面体方向编码 → 全局 2D 纹理图集
1.3 与其他 GI 方案的定位
DDGI 在实时 GI 谱系中的位置:
| 方案 |
计算位置 |
频率特点 |
动态性 |
DDGI 角色 |
| Light Map (烘焙) |
离线 |
高频细节 |
静态 |
DDGI 替代它 |
| Light Probes (烘焙) |
离线 + 运行时插值 |
低频 |
静态 |
DDGI 替代它 |
| SSGI / SSAO |
后期屏幕空间 |
中频,仅屏幕内 |
即时 |
与 DDGI 互补 |
| RSM / VPL |
实时 |
中频 |
准实时 |
DDGI 替代它 |
| DDGI |
实时光追 + 缓存 |
低频漫反射 |
完全动态 |
本笔记 |
| ReSTIR GI |
实时光追 + 重采样 |
中-高频 |
完全动态 |
处理 DDGI 不擅长的尖锐特征 |
| Lumen Surface Cache |
实时多 LOD |
中频 |
完全动态 |
与 DDGI 同生态位 |
💡 工程经验:DDGI 不是万能 GI,它擅长漫反射间接光的低频部分。镜面反射、清晰的接触阴影 GI、彩色阴影边缘等高频特征,仍需 SSR / 屏幕空间接触阴影 / ReSTIR 等额外手段补充。
二、数据结构与存储布局
⚠️ 八面体映射的方向 ↔ UV 转换数学(含 sign 折叠、对角对称等)已在另一篇笔记中详述。本节仅复述 DDGI 中的具体使用方式与图集布局。
八面体编码
阅读前置:八面体映射(Octahedral Mapping)的方向↔UV
2.1 两个核心纹理图集
DDGI 为每个探针保存两份八面体编码的数据:
| 名称 |
每探针分辨率 |
存储内容 |
数据精度 |
| Irradiance Atlas |
6×6 (内核) + 1px border × 2 = 8×8 |
余弦权重的辐照度 (RGB) |
RGB10A2 / RGBA16F |
| Distance Atlas |
14×14 + 1px border × 2 = 16×16 |
(mean、mean square distance) |
RG16F |
为什么 distance 分辨率高 4 倍?因为可见性查询需要更精细的方向区分——少量像素无法表达”墙边缘”等几何高频特征。Irradiance 是低频的,6×6 已经足够。
2.2 Border Padding:边界填充的必要性
八面体贴图的两条边在球面上是相邻的(边界折叠)。如果直接采样,硬件双线性插值会跨越接缝读取错误像素。
解决方案:每个探针的有效区域外加 1 像素 border,手动填充对侧像素的值。这样硬件双线性可以无缝跨越边界。
1
2
3
4
5
6
7
8
9
10
| 有效内核 6×6: 带 border 的 8×8 物理布局:
. . . . . . X 5 4 3 2 1 0 X
. . . . . . 5 . . . . . . 0
. . . . . . 4 . . . . . . 1
. . . . . . → 3 . . . . . . 2
. . . . . . 2 . . . . . . 3
. . . . . . 1 . . . . . . 4
0 . . . . . . 5
X 0 1 2 3 4 5 X
|
四个角是对角线对称像素,边的像素是镜像复制。
2.3 全局图集布局
整个 volume(如 16×8×16 = 2048 探针)的数据被打包为一个大 2D 纹理:
1
2
| texSize.x = (probeCountX × probeCountY) × probeRes
texSize.y = probeCountZ × probeRes
|
例如 8 像素 irradiance + 8×8×8 探针:
1
| ProbeAtlasSize = (8×8 × 8, 8 × 8) = (512, 64)
|
采样某个探针的某个方向时:
1
2
3
4
5
6
| float2 texelCoord = OctEncode(direction) * (PROBE_RES - 2) + 1; // 内核区域
uint probeIdx = probeY * countXZ + probeZ * countX + probeX;
uint2 probeBase = uint2((probeIdx % atlasCols) * (PROBE_RES + 2),
(probeIdx / atlasCols) * (PROBE_RES + 2));
float2 atlasUV = (probeBase + texelCoord) / atlasSize;
return texAtlas.SampleLevel(sampler_linear, atlasUV, 0);
|
2.4 内存预算估算
每探针:
| Volume 规模 |
探针数 |
显存 |
适用场景 |
| 8×4×8 |
256 |
~320 KB |
小型房间 |
| 16×8×16 |
2048 |
~2.5 MB |
中型场景(一个关卡) |
| 32×16×32 |
16384 |
~20 MB |
大型室内场景 |
| 64×32×64 (级联) |
131072 |
~160 MB |
开放世界(需滚动) |
💡 经验法则:探针密度建议 1~2 米/探针。对内存敏感的项目可以降到 4 米/探针并配合更激进的视觉接触阴影补偿。
三、攻克顽疾:可见性与漏光处理
这是 DDGI 最核心的数学创新,也是它能投入生产环境最关键的一步。整个第三节是必读重点。
3.1 漏光问题的本质
考虑一个经典 corner case:
问题诊断:着色点 位于墙的右侧(背光),其 8 个最近探针中可能有些位于墙左侧(被光照亮)。如果只用三线性插值(仅基于距离),P1 会贡献光给 X——光”穿墙”了。
人眼对漏光极其敏感——黑暗角落里突然亮起来一片,立刻显得”假”。修复漏光是 DDGI 论文最重要的工程贡献。
3.2 切比雪夫不等式:从概率论借的核武器
标准切比雪夫不等式:对于均值 、方差 的随机变量 ,
单边形式(One-tailed Chebyshev / Cantelli’s inequality):当 时,
这个公式正是 Variance Shadow Map (VSM) 用来估计阴影遮挡概率的工具。DDGI 借用了完全相同的数学结构。
3.3 在 DDGI 中的物理对应
把”探针在某方向上记录的击中距离”视为随机变量:
| 切比雪夫符号 |
DDGI 对应 |
| 随机变量 |
探针 在方向 上的射线击中距离 |
| 均值 |
探针存储的 |
| 方差 |
|
| 查询值 |
着色点 到探针 的距离 |
| 上界 |
“探针 能看到 ”的概率上界 |
直觉:如果探针记录到该方向射线平均跑了 1 米就撞墙(, 很小),但着色点 距探针 3 米——那么从探针到 的视线几乎肯定被那堵墙挡住。切比雪夫给出的上界自动接近 0。
反之,如果探针没遮挡( 接近 sceneRadius, 大),上界保持接近 1,权重正常。
3.4 实际公式与 VSM-style 简化
DDGI 实践中使用的变体(来自 [Majercik 2019] §5.3):
注意当 时直接返回 1——这意味着”如果着色点比平均击中距离更近,肯定看得到”。这是一个安全但略保守的简化。
工程实现:
1
2
3
4
5
6
7
8
| float chebyshevVisibility(float meanDist, float meanSqDist, float distToProbe) {
float variance = abs(meanDist * meanDist - meanSqDist);
// ↑ 注意:因为 atlas 用 EMA 混合的精度损失,可能轻微为负
float t = distToProbe;
if (t <= meanDist) return 1.0;
float diff = t - meanDist;
return variance / (variance + diff * diff);
}
|
3.5 进一步:Sharpen 因子与权重压扁
切比雪夫给的是上界,不是真实概率。论文发现直接用会让”半遮挡”区域过亮。改进:
幂次 让权重曲线”陡峭化”,遮挡边缘更接近 0。RTXGI SDK 默认 。
3.6 交互式演示:切比雪夫可见性权重计算器
下面这个 widget 让我们直观感受 如何决定可见性权重。橙色高斯曲线表示距离分布,蓝色竖线是查询距离 ,红色面积是 ,最右侧实时显示切比雪夫权重值。
📐 切比雪夫可见性权重交互
σ² = 0.25 | (t - μ) = 1.50 | chebyshev = 0.10 | sharpened³ = 0.001
💡 试试这些场景:
(1) 把 t 拉到小于 μ → 权重恒为 1(看得到);
(2) 把 σ 调小、t 远大于 μ → 权重→0(被挡,不漏光);
(3) σ 大 + t 略大于 μ → 权重保持较高(半遮挡区域)。
🎯 关键观察:滑动 t 让它穿过 μ,可见性权重从 1.0 平滑过渡到接近 0。σ 越小(探针记录的距离越确定,比如紧贴墙体),过渡越剧烈——这正是我们想要的”硬边缘漏光抑制”。
3.7 完整权重组合:三线性 × 法线 × 可见性
最终从 8 个最近探针采样的权重是三个分量相乘:
1. 三线性权重 :基于 在探针网格 cell 内的位置(标准三线性插值)。
2. 法线/背面权重 :抑制位于 几何背面的探针:
其中 。背面 () 的探针权重平滑→0。
3. 可见性权重 :本节核心,切比雪夫 + sharpen。
最终:
点击展开查看代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
| float3 sampleIrradiance(float3 worldPos, float3 normal) {
int3 baseProbeCoord = worldToProbeCoord(worldPos - probeOrigin);
float3 alpha = frac((worldPos - probeOrigin) / probeSpacing);
float3 sumIrradiance = 0;
float sumWeights = 0;
[unroll]
for (int i = 0; i < 8; ++i) {
int3 offset = int3(i, i>>1, i>>2) & 1;
int3 probeCoord = baseProbeCoord + offset;
float3 probePos = probeCoordToWorld(probeCoord);
float3 toProbe = probePos - worldPos;
float distToProbe = length(toProbe);
float3 dirToProbe = toProbe / distToProbe;
float3 wT3 = lerp(1.0 - alpha, alpha, float3(offset));
float trilinear = wT3.x * wT3.y * wT3.z;
float backWeight = pow(saturate(dot(dirToProbe, normal) * 0.5 + 0.5), 2);
float2 dist = sampleDistance(probeCoord, dirToProbe);
float variance = abs(dist.x*dist.x - dist.y);
float chebyshev = 1.0;
if (distToProbe > dist.x) {
float diff = distToProbe - dist.x;
chebyshev = variance / (variance + diff*diff);
chebyshev = pow(max(0, chebyshev), 3);
}
float weight = trilinear * backWeight * chebyshev;
weight = max(weight, 1e-6);
float3 irradiance = sampleIrradianceAtlas(probeCoord, normal);
sumIrradiance += weight * irradiance;
sumWeights += weight;
}
return sumIrradiance / sumWeights;
}
|
3.8 2D 截面演示:8 探针的权重综合
下面这个 widget 可以在 2D 场景中拖动着色点,实时看到每个探针的可见性权重如何综合 trilinear + chebyshev:
🏠 2D 场景:探针权重合成(拖动红点)
Drag the red point to see weights update.
🎯 关键实验:把红点拖到墙的右侧(背光侧),观察”亮探针权重”。
- Chebyshev ON:墙左侧的亮探针权重接近 0%(虚线),右侧暗探针权重接近 100% → 黑暗符合预期
- Chebyshev OFF:左侧亮探针权重大幅贡献 → 漏光!
四、算法管线:每帧 GPU 在做什么
4.1 三阶段管线总览
4.2 阶段 ①:探针光线追踪(Ray Generation)
每帧每个探针发射 条射线(典型 )。射线方向通过球面斐波那契采样均匀分布,并加每帧旋转扰动以避免方向偏置。
4.2.1 球面斐波那契采样
最常用方法是Fibonacci spiral(也叫 Fibonacci lattice):
1
2
3
4
5
6
7
| float3 sphericalFibonacci(uint i, uint N) {
const float PHI = 1.6180339887498949;
float phi = 2.0 * 3.14159265 * (i / PHI);
float z = 1.0 - (2.0 * i + 1.0) / float(N);
float r = sqrt(saturate(1.0 - z*z));
return float3(r * cos(phi), r * sin(phi), z);
}
|
每帧用一个 random rotation matrix 旋转所有方向,避免静态采样模式:
1
2
| float3x3 randomRotation = makeRotation(perFrameRandomQuaternion);
float3 dir = mul(randomRotation, sphericalFibonacci(rayIdx, RAYS_PER_PROBE));
|
4.2.2 交互式:球面斐波那契采样可视化
下面这个 widget 让我们直观感受 Fibonacci 采样如何均匀覆盖球面,并对比”伪球面采样”(球坐标 uniform)的极点聚集问题:
🌀 球面采样方法对比(拖动旋转)
Fibonacci 给出的样本相邻间距均匀,covering 半径几乎最优(接近
)。
🎯 观察重点:切换到”球坐标 uniform”,会看到南北极聚集严重(covering 不均)。Fibonacci 在所有 N 下都给出近似均匀的分布——这正是它在 DDGI 中被采用的原因。
4.2.3 射线击中点 shading
每条射线击中场景表面 后,计算其入射光(这一步本身就是一次”小型” path tracing):
C
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| struct RayPayload {
float3 radiance;
float distance;
bool hitBackface;
};
void traceProbeRay(float3 probePos, float3 dir, out RayPayload payload) {
HitInfo hit = traceRay(probePos, dir);
if (!hit.valid) {
payload.radiance = sampleSky(dir);
payload.distance = 1e6;
payload.hitBackface = false;
return;
}
if (dot(hit.normal, -dir) <= 0) {
payload.distance = -hit.t * 0.2;
payload.radiance = 0;
payload.hitBackface = true;
return;
}
float3 directL = computeDirectLighting(hit);
float3 indirectL = sampleIrradiance(hit.pos, hit.normal) * hit.albedo / PI;
payload.radiance = directL + indirectL;
payload.distance = hit.t;
payload.hitBackface = false;
}
|
🔑 “无限反弹”魔法:注意第 19 行——击中点的间接光直接采样上一帧的 DDGI atlas。这就是为什么 DDGI 的反弹深度是”理论无限”的:每帧把上帧的 GI 注入新的 ray hit shading,几帧后整个 atlas 收敛到包含所有反弹的稳态值。
4.2.4 Backface Hit 的特殊处理
当射线击中三角形背面时,距离写入 (论文 Algorithm 2)。负数能让切比雪夫读到时立刻识别”这个方向遭遇异常”,进一步保护薄墙不漏光。
具体来说,在 distance update 阶段,背面命中既贡献”压缩后的小距离”也贡献相应的小方差——使得任何穿越该方向的查询路径都会被严重抑制。
4.3 阶段 ②:Probe Update(指数移动平均)
4.3.1 EMA 更新公式
设 是历史权重(hysteresis), 是当帧某 texel 的新观察值, 是 atlas 中已有的值:
典型值:。这相当于”33 帧的指数滑动窗口”——单一射线噪声在 33 帧内被平滑掉,但场景动态变化也需 ~33 帧才能完全更新。
💡 权衡: 越接近 1 → 越稳定但越慢响应; 越小 → 响应快但闪烁严重。 是 [Majercik 2019] 的推荐起点。Cyberpunk 用了自适应 α:场景剧变时(如开门、爆炸)短暂降到 0.85 加快收敛。
4.3.2 单 Texel 更新逻辑
每个 texel 对应八面体上的某个方向区间 。当帧的 条射线方向都不一定恰好落在 上——所以需要按余弦权重聚合所有射线对该 texel 的贡献:
工程上,每个 texel 的 compute thread 遍历当前探针的所有射线,对每条射线检查”是否在 texel 的半球内”(cosine > 0),按 cosine 加权累加。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
[numthreads(PROBE_RES, PROBE_RES, 1)]
void UpdateIrradianceProbe(uint3 tid : SV_DispatchThreadID,
uint3 gid : SV_GroupID) {
uint probeIdx = gid.x;
float2 octUV = (float2(tid.xy) + 0.5) / PROBE_RES;
float3 texelDir = octDecode(octUV * 2 - 1);
float3 sumIrr = 0;
float sumWeight = 0;
for (int i = 0; i < RAYS_PER_PROBE; ++i) {
float3 rayDir = readRayDir(probeIdx, i);
float3 rayRad = readRayRadiance(probeIdx, i);
float weight = max(0, dot(texelDir, rayDir));
weight = pow(weight, 50);
sumIrr += rayRad * weight;
sumWeight += weight;
}
if (sumWeight > 1e-6) sumIrr /= sumWeight;
float3 prev = g_irradianceAtlas[atlasCoord].rgb;
float3 blended = lerp(sumIrr, prev, hysteresis);
g_irradianceAtlas[atlasCoord] = float4(blended, 1);
}
|
4.3.3 Distance 图集的特殊性
距离图集存的是 pair,不能用线性 EMA 直接平均 ——更准确的做法是单独累积 和 各自的 EMA。
1
2
3
| float2 prev = g_distanceAtlas[atlasCoord].rg;
float2 newD = float2(weightedMeanDist, weightedMeanDist*weightedMeanDist);
g_distanceAtlas[atlasCoord] = lerp(newD, prev, hysteresis);
|
4.3.4 Border Padding 复制
最后一步:把内核区域 (6×6) 周围的 border 像素填充为对侧值。一个独立 compute pass 处理:
1
2
3
4
5
6
7
8
| [numthreads(8, 1, 1)]
void CopyBorder(uint3 tid : SV_DispatchThreadID) {
// tid.x 表示 border 上的位置
// 根据八面体折叠规则,从内核对侧像素读取
int2 borderTex = computeBorderCoord(tid.x);
int2 sourceTex = computeOppositeKernelCoord(tid.x);
g_atlas[borderTex] = g_atlas[sourceTex];
}
|
4.4 阶段 ③:Shading 时的探针采样
在主 shading pass,对每个像素查 8 个邻探针。完整代码见 §3.7。
性能优化技巧:
- 不要在每个像素都做 8 次完整切比雪夫——先用 trilinear 权重 cull 掉权重 < 0.001 的探针
- Distance atlas 用单独 sampler with bilinear filtering
- 探针位置对内存布局优化:把同一 cell 的 8 个探针索引放在连续内存,提高 cache 命中
4.5 完整 RTXGI-style 帧时间分配
[Majercik 2021] 在 RTX 3080 上的实测(探针数 16K,每探针 144 rays):
| 阶段 |
时间 |
占比 |
| Probe Ray Trace |
1.8 ms |
51% |
| Probe Update (Irradiance) |
0.6 ms |
17% |
| Probe Update (Distance) |
0.4 ms |
11% |
| Border Copy |
0.1 ms |
3% |
| Shading Sample |
0.6 ms |
17% |
| 总计 |
3.5 ms |
100% |
为参考:同场景下 ReSTIR DI ~2 ms,ReSTIR PT ~6 ms,Lumen 全 stack ~4 ms。
五、工程优化与生产落地
论文中的”裸 DDGI”在生产中会遇到一系列工程难题:探针放在墙内浪费、开放世界探针装不下、探针数过多导致每帧追光开销爆炸。[Majercik 2021] 与 RTXGI SDK 给出了系统性解决方案。
5.1 探针状态管理 (Probe Classification)
问题:探针网格中大量探针位于无效位置——
- 嵌入墙体内部(永远黑暗,更新它没意义)
- 完全空旷区域(所有射线 miss,浪费追光预算)
- 远离任何 shading point(没人会采样它)
解决:每个探针带一个 state 字段,每帧动态分类。
5.1.1 探针状态枚举
1
2
3
4
5
6
| enum ProbeState {
PROBE_ACTIVE = 0,
PROBE_INACTIVE = 1,
PROBE_VIGILANT = 2,
PROBE_OFF = 3,
};
|
5.1.2 分类启发式
每帧(或每几帧)一次分类 pass:
| 信号 |
含义 |
状态影响 |
| 大部分射线击中背面 |
探针在墙体内 |
→ OFF |
| 大部分射线 miss(飞到天空) |
探针在大空旷处 |
→ VIGILANT |
| 探针距相机 > active radius |
玩家暂时看不到 |
→ INACTIVE |
| 探针周围 cell 被像素采样过 |
玩家正在看 |
→ ACTIVE |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| [numthreads(64, 1, 1)]
void ClassifyProbes(uint3 tid : SV_DispatchThreadID) {
uint probeIdx = tid.x;
if (probeIdx >= numProbes) return;
// 统计上帧射线击中模式
int backfaceHits = 0, missHits = 0, frontHits = 0;
for (int i = 0; i < RAYS_PER_PROBE; ++i) {
float dist = readRayDistance(probeIdx, i);
if (dist >= INFINITY_THRESHOLD) missHits++;
else if (dist < 0) backfaceHits++;
else frontHits++;
}
float frontRatio = frontHits / float(RAYS_PER_PROBE);
float backRatio = backfaceHits / float(RAYS_PER_PROBE);
ProbeState newState = PROBE_ACTIVE;
if (backRatio > 0.5) newState = PROBE_OFF; // 嵌墙
else if (frontRatio < 0.05) newState = PROBE_VIGILANT; // 空旷
// 距相机过远 → INACTIVE
float3 probePos = computeProbePos(probeIdx);
if (distance(probePos, cameraPos) > activeRadius)
newState = PROBE_INACTIVE;
g_probeState[probeIdx] = newState;
}
|
5.1.3 动态射线预算分配
不同状态的探针在 ray gen 阶段被不同对待:
| 状态 |
射线数 |
触发条件 |
ACTIVE |
144 / 256 (full budget) |
玩家视野附近 |
VIGILANT |
32 (低频) |
远场探针 |
INACTIVE |
0(每 N 帧 1 次唤醒检查) |
暂停 |
OFF |
0(永久休眠直到位置变化) |
墙内 |
实测收益:典型场景 50-70% 的探针处于 OFF 或 INACTIVE,整体追光开销下降 3-5 倍。
5.1.4 探针位置偏移 (Probe Relocation)
进一步优化:检测到探针嵌墙时,自动微调位置 [Majercik 2021]。
1
2
3
4
5
6
7
8
9
10
11
| // 沿"最常击中背面"方向反向推移
float3 offset = 0;
for (int i = 0; i < RAYS_PER_PROBE; ++i) {
float dist = readRayDistance(probeIdx, i);
if (dist < 0) { // backface hit
float3 dir = readRayDir(probeIdx, i);
offset -= dir * abs(dist) * 1.5;
}
}
offset = clamp(offset, -probeSpacing*0.5, probeSpacing*0.5);
g_probeOffsets[probeIdx] = offset; // 限制在 cell 半径内
|
最终探针采样位置 = 网格基准位置 + offset。这让原本”卡墙里”的探针自动跳到墙外的有效区域,避免无效探针浪费。
⚠️ 注意:探针位置偏移会破坏 trilinear 插值的均匀性假设。[Majercik 2021] 给出了带 offset 的修正插值公式(实战中通常用规则网格 + per-probe small offset 的近似处理就够)。
问题:开放世界场景太大,无法在整个世界铺满探针。
思路:参考级联阴影 (CSM) 的设计——
- 多个 volume,越靠近相机分辨率越高
- 每个 volume 跟随相机移动,只更新边缘新进入的探针
5.2.1 多级 Volume 配置
| Cascade |
Spacing |
Volume 半径 |
探针总数 |
| L0 (close) |
0.5 m |
16 m |
32×8×32 = 8192 |
| L1 (medium) |
2 m |
64 m |
32×8×32 = 8192 |
| L2 (far) |
8 m |
256 m |
32×8×32 = 8192 |
总探针数固定(24576),覆盖范围呈几何级数扩展。
5.2.2 滚动更新机制
当相机移动时,volume 中心跟随,但网格保持对齐到全局世界坐标(避免抖动):
1
2
3
4
5
6
7
8
9
10
11
|
int3 newOriginCell = roundToInt(cameraPos / probeSpacing);
int3 deltaCells = newOriginCell - oldOriginCell;
if (any(abs(deltaCells)) > 0) {
for (each axis a where deltaCells[a] != 0) {
markDirtyRegion(deltaCells, a);
}
}
|
类比:把 atlas 当作环形缓冲区。相机往 +X 移 1 cell,最左侧一列探针被”环绕”到最右侧并标记为脏,下一帧用 full ray budget 完整初始化。
5.2.3 多级混合时的 Cascade Selection
Shading 时,根据像素位置选择合适的 cascade:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| float3 sampleIrradianceMulti(float3 worldPos, float3 normal) {
// 优先用最高分辨率 cascade
for (int c = 0; c < NUM_CASCADES; ++c) {
float3 localPos = worldPos - cascadeOrigin[c];
if (all(abs(localPos) < cascadeRadius[c])) {
float3 result = sampleSingleCascade(c, worldPos, normal);
// 在 cascade 边缘 fade 到下一级
float fadeStart = cascadeRadius[c] * 0.85;
float t = saturate((max3(abs(localPos)) - fadeStart) /
(cascadeRadius[c] - fadeStart));
if (t > 0 && c+1 < NUM_CASCADES) {
float3 nextResult = sampleSingleCascade(c+1, worldPos, normal);
result = lerp(result, nextResult, t);
}
return result;
}
}
return sampleSky(normal); // 全部 cascade 之外用 IBL fallback
}
|
5.3 多 Volume:手动放置式 vs 跟随相机式
两种部署策略:
| 策略 |
优点 |
缺点 |
适用 |
| 跟随相机的滚动级联 |
自动化,开放世界友好 |
远场细节差,相机静止时浪费更新 |
大世界 RPG |
| 关卡设计师手放 Volume |
室内场景精准控制,密度可定制 |
开放世界不可行 |
线性关卡 / 室内 |
实战常采用混合方案:
- 关卡设计师在重要室内空间放高密度小 Volume
- 室外用相机跟随的级联做兜底
- Shading 时优先级:手放 Volume > 级联 > 反射探针 fallback
5.4 抗噪与时间稳定性进阶
5.4.1 Variance Clamp + EMA Bias 抑制
EMA 在场景剧变时(开/关大灯、爆炸)会出现可见 lag。改进 [Cyberpunk 经验]:
1
2
3
4
5
6
7
8
9
10
11
| float adaptiveAlpha(float3 newSample, float3 oldSample, float defaultAlpha) {
// 检测大幅变化
float diff = length(newSample - oldSample);
float magnitude = max(luminance(oldSample), 0.01);
float relChange = diff / magnitude;
// 大变化 → 降低 alpha,让新值占更多权重
if (relChange > 1.0) return 0.85; // 大变化
if (relChange > 0.3) return 0.93; // 中等
return defaultAlpha; // 0.97 默认
}
|
5.4.2 Tone-mapped EMA
直接对 HDR 颜色做 EMA 在极亮像素附近会有”细节丢失”问题。改进:
1
2
3
4
5
6
7
8
| float3 toneMap(float3 c) { return c / (1.0 + luminance(c)); }
float3 invToneMap(float3 c) { return c / max(1.0 - luminance(c), 0.001); }
// EMA in tone-mapped space
float3 prevTM = toneMap(prev);
float3 newTM = toneMap(newSample);
float3 mixed = lerp(newTM, prevTM, alpha);
result = invToneMap(mixed);
|
5.4.3 Light Response Threshold
某些场景(炮弹爆炸瞬间)单帧出现极端亮值,会让 EMA 长期”中毒”:
1
2
| // firefly suppression
float3 newClamped = min(newSample, 32.0 * luminance(prev) + 1.0);
|
5.5 内存压缩选择
| 数据 |
朴素 |
压缩 |
节省 |
| Irradiance |
RGBA32F (16B) |
RGB10A2 (4B) |
75% |
| Distance |
RG32F (8B) |
RG16F (4B) |
50% |
💡 注意:Irradiance 用 RGB10A2 时要先做 sRGB-like gamma curve 编码(实际上是 ),否则 10-bit 远不够 HDR 动态范围。
5.6 与降噪 / TAA 的协同
DDGI 的输出本身就经过 EMA 时间平滑——通常不再需要额外的时空降噪器。但仍要注意:
- DDGI 的”空间分辨率”由探针密度决定,比像素低很多
- 在像素级 shading 时插值已经平滑,但接触阴影 (AO) 仍需独立处理
- 镜面反射部分用屏幕空间反射 (SSR) 或 ReSTIR 单独处理,不走 DDGI
与 DLSS / FSR 的协同:DDGI 输出对低分辨率下的双线性放大很友好,因为本身就是低频信号。Cyberpunk 的实测中 DDGI 输出可以以 50% 屏幕分辨率计算后用 DLSS 直接放大,质量损失几乎不可察觉。
六、与其他 GI 方案对比
6.1 DDGI vs ReSTIR GI
| 维度 |
DDGI |
ReSTIR GI |
| 采样位置 |
网格探针,离散 |
每像素 |
| 存储格式 |
八面体 atlas |
Per-pixel reservoir |
| 频率特点 |
低频漫反射 |
中-高频,含 sharp features |
| 接触阴影 |
弱(探针密度限制) |
强 |
| 首帧质量 |
EMA 需 ~30 帧收敛 |
1 spp 就接近收敛 |
| 动态光适应 |
受 alpha 限制 |
即时 |
| 内存 |
几十 MB(atlas) |
几十-几百 MB(reservoir) |
| 大场景 |
滚动级联好 |
像素数限制 |
| 典型用途 |
GI 底色 / 兜底 |
直接光 / 高频细节 |
💡 结合:DDGI + ReSTIR 是当代旗舰游戏的常见组合(如 Cyberpunk RT mode)。
6.2 DDGI vs Lumen Surface Cache
| 维度 |
DDGI |
Lumen Surface Cache |
| 缓存位置 |
3D 网格点(探针) |
mesh 表面(cards) |
| 几何依赖 |
只依赖位置,与 mesh 解耦 |
强耦合到 mesh 拓扑 |
| 优势 |
简单,统一处理任意场景 |
几何体表面信息更充分 |
| 劣势 |
大空场景探针浪费 |
复杂动态场景 cache 失效 |
| 硬件 RT 依赖 |
强 |
可不用(SDF + screen trace) |
| 生态成熟度 |
多家公司 / 学术界 |
UE5 紧耦合 |
6.3 DDGI vs SH Probe(传统)
| 维度 |
DDGI |
SH (球谐) Probe |
| 方向编码 |
八面体 (低失真) |
SH 系数(L2/L3) |
| 存储 |
atlas (高分辨率) |
9 / 16 floats per probe |
| 方向分辨率 |
6x6 = 36 个 texel |
9 个系数(极低频) |
| 更新方式 |
实时光追 + EMA |
烘焙 / 周期重算 |
| 优势 |
高频 GI + 完全动态 |
极致内存效率 |
| 劣势 |
内存大 |
频率 cap 低,无法表达硬阴影 |
6.4 选型决策树
1
2
3
4
5
6
7
8
9
10
11
12
| 是否需要完全动态 GI?
├─ 否 → 用烘焙 lightmap / SH probe,省 90% GPU
└─ 是 ↓
是否有 RT 硬件?
├─ 否 → Lumen / SDF-based / VXGI
└─ 是 ↓
场景规模?
├─ 小型室内 (< 100m³) → DDGI 单 volume,足够
├─ 中型关卡 (100-1000m³) → DDGI 多 volume + 关卡设计师手放
└─ 大型开放世界 → DDGI 滚动级联 + Lumen Surface Cache fallback
是否需要锐利的接触 GI / specular?
└─ 是 → 在 DDGI 上叠加 ReSTIR DI/GI / SSR / contact AO
|
七、参考资料
核心论文
- [Majercik et al. 2019] Dynamic Diffuse Global Illumination with Ray-Traced Irradiance Fields — DDGI 原始论文 JCGT 8(2)
- [Majercik et al. 2021] Scaling Probe-Based Real-Time Dynamic Global Illumination for Production — 工程化扩展 JCGT 10(2)
- [Heitz et al. 2018] Combining Analytic Direct Illumination and Stochastic Shadows — VSM-style 方差遮挡的更早期文献
- [Donnelly & Lauritzen 2006] Variance Shadow Maps — 切比雪夫不等式在阴影中的开创性应用,DDGI 漏光防护的数学源头
课程与讲座
开源实现
中文解读
进一步阅读
- VXGI [Crassin 2011]:体素化的 GI,DDGI 之前的常见动态方案
- SVO Cone Tracing [Crassin 2012]:稀疏体素八叉树 GI
- NVIDIA Lumen-style Surface Cache — UE5 的另一条路线
- ReSTIR GI / PT — 与 DDGI 互补的高频 GI 方案(见我之前的笔记)
附录 A:核心公式速查表
11.1 公式总览
| 公式 |
用途 |
备注 |
|
漫反射出射 |
基础渲染方程 |
|
DDGI 核心近似 |
8 探针加权 |
|
切比雪夫不等式(Cantelli) |
单边形式 |
|
方差从二阶矩 |
atlas 直接读 |
|
可见性权重 |
|
|
背面权重 |
防探针在背面 |
|
总权重 |
三项乘积 |
|
EMA |
|
| , , |
Fibonacci 球面采样 |
黄金比 |
11.2 Texel 余弦权重聚合公式
经验值 (论文 §6)。
11.3 实战参数推荐起点
| 参数 |
推荐值 |
备注 |
| Probe spacing |
1.0 m (室内) / 4.0 m (室外) |
越密越准但越费 |
| Probe volume size |
16×8×16 起步 |
关卡尺寸决定 |
| Rays per probe |
144 |
平衡质量/成本 |
| Hysteresis |
0.97 |
静态用 0.98+,动态用 0.93- |
| Irradiance probe res |
6×6 (kernel) + 2 border = 8×8 |
标配 |
| Distance probe res |
14×14 + 2 border = 16×16 |
标配 |
| Chebyshev sharpen power |
3 |
控制漏光过渡硬度 |
| Backface relocation distance |
0.5 × spacing |
上限 |
| Active radius |
64 m |
内 ACTIVE,外 INACTIVE |
| Fibonacci rotation |
每帧 random quaternion |
抗采样偏置 |
附录 B:完整 DDGI Probe Update Compute Shader 骨架
DDGI
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
|
cbuffer DDGIConstants {
float3 volumeOrigin;
float3 probeSpacing;
int3 probeCounts;
int raysPerProbe;
float hysteresis;
float maxRayDistance;
int irrProbeRes;
int distProbeRes;
float4 randomRotation;
};
StructuredBuffer<float3> g_rayDirections;
StructuredBuffer<float4> g_rayPayloads;
RWTexture2D<float4> g_irradianceAtlas;
RWTexture2D<float2> g_distanceAtlas;
RWStructuredBuffer<int> g_probeStates;
RWStructuredBuffer<float3> g_probeOffsets;
float3 octDecode(float2 e) {
float3 v = float3(e, 1.0 - abs(e.x) - abs(e.y));
if (v.z < 0) v.xy = (1 - abs(v.yx)) * sign(v.xy);
return normalize(v);
}
uint2 probeBaseTexel(uint probeIdx, int probeRes) {
int probeWithBorder = probeRes + 2;
int probesPerRow = probeCounts.x * probeCounts.z;
uint y = probeIdx / probesPerRow;
uint x = probeIdx % probesPerRow;
return uint2(x * probeWithBorder + 1, y * probeWithBorder + 1);
}
[numthreads(6, 6, 1)]
void UpdateIrradianceProbe(uint3 tid : SV_DispatchThreadID,
uint3 gid : SV_GroupID,
uint3 ltid : SV_GroupThreadID) {
uint probeIdx = gid.x;
if (g_probeStates[probeIdx] == PROBE_OFF) return;
float2 octUV = (float2(ltid.xy) + 0.5) / float(irrProbeRes);
octUV = octUV * 2.0 - 1.0;
float3 texelDir = octDecode(octUV);
float3 sumRad = 0;
float sumW = 0;
for (int i = 0; i < raysPerProbe; ++i) {
float3 rayDir = g_rayDirections[probeIdx * raysPerProbe + i];
float4 payload = g_rayPayloads[probeIdx * raysPerProbe + i];
float3 rayRad = payload.rgb;
float w = max(0, dot(texelDir, rayDir));
w = pow(w, 50);
sumRad += rayRad * w;
sumW += w;
}
float3 irrNew = (sumW > 1e-6) ? (sumRad / sumW) : 0;
uint2 texel = probeBaseTexel(probeIdx, irrProbeRes) + ltid.xy;
float3 irrPrev = g_irradianceAtlas[texel].rgb;
float diffMag = length(irrNew - irrPrev) / max(luminance(irrPrev), 0.01);
float alpha = hysteresis;
if (diffMag > 1.0) alpha = lerp(hysteresis, 0.85, saturate(diffMag - 1));
float3 blended = lerp(irrNew, irrPrev, alpha);
g_irradianceAtlas[texel] = float4(blended, 1.0);
}
[numthreads(14, 14, 1)]
void UpdateDistanceProbe(uint3 tid : SV_DispatchThreadID,
uint3 gid : SV_GroupID,
uint3 ltid : SV_GroupThreadID) {
uint probeIdx = gid.x;
if (g_probeStates[probeIdx] == PROBE_OFF) return;
float2 octUV = (float2(ltid.xy) + 0.5) / float(distProbeRes);
octUV = octUV * 2.0 - 1.0;
float3 texelDir = octDecode(octUV);
float meanDist = 0, meanSqDist = 0, sumW = 0;
for (int i = 0; i < raysPerProbe; ++i) {
float3 rayDir = g_rayDirections[probeIdx * raysPerProbe + i];
float dist = g_rayPayloads[probeIdx * raysPerProbe + i].w;
if (dist < 0) dist = abs(dist);
float w = max(0, dot(texelDir, rayDir));
w = pow(w, 50);
meanDist += dist * w;
meanSqDist += dist * dist * w;
sumW += w;
}
if (sumW > 1e-6) {
meanDist /= sumW;
meanSqDist /= sumW;
}
uint2 texel = probeBaseTexel(probeIdx, distProbeRes) + ltid.xy;
float2 prev = g_distanceAtlas[texel];
float2 newD = float2(meanDist, meanSqDist);
g_distanceAtlas[texel] = lerp(newD, prev, hysteresis);
}
|