
一、背景与摘要
在现代 3D 游戏引擎(如虚幻 5 的 Nanite 早期思想、各种开放世界引擎)中,庞大世界的渲染 是一个绕不开的核心挑战。一个 10km × 10km 量级的开放世界,若简单地把所有地块网格交给 CPU 遍历并提交 DrawCall,CPU 端的剔除遍历开销与GPU 端的顶点处理开销 会双双爆炸,性能瓶颈几乎是必然。
破局思路并不是一蹴而就的。本文将沿着 “从基础概念到进阶演化”的脉络,分三步推进:
- 理论打底:先建立”四叉树/八叉树空间剔除”的基本认知,理解为什么空间划分能加速剔除;
- CPU 原型:用 Unity 的
Graphics.DrawMeshInstanced与GeometryUtility实现一个最小可用的四叉树剔除原型,看清它的能力边界; - GPU 进化:当原型在大世界规模下力不从心时,自然过渡到 GPU-Driven Terrain 架构——将四叉树遍历、LOD 评估、剔除全部搬到 Compute Shader 中。
尽管图形渲染的脏活累活交给了 GPU,但游戏玩法层面的逻辑(如角色高度查询、物理碰撞、地表材质判定)依然在 CPU 端运行。因此,系统需要在 CPU 端保留一份独立的、专门用于游戏玩法查询的地形数据结构。
本文 GPU 部分主要参考孤岛惊魂5地形渲染的设计思路,并结合项目实现,逐步介绍 GPU Driven Terrain 的核心知识。
二、理论基础:四叉树与空间剔除
1. 什么是四叉树 / 八叉树?

四叉树的构建过程非常直观:
- 取一个空间区域,将该区域分配给根节点;
- 把该空间分为4 个相等的部分,作为根节点的子节点;
- 持续此过程——每个空间继续四等分,分配给下一层子节点;
- 直到达到设定的深度或停止条件,没有子节点的节点称为叶节点。

用三维建模的术语来说,这就像对网格进行细分(Subdivide)。
八叉树(OcTree)是同样的概念,但它在Y 轴上也会进行划分——每个空间被切成 8 个相等的部分,而不是 4 个。当数据在垂直方向上变化剧烈时(例如装满方块的立方体空间),八叉树能给出更紧凑的边界。
2. 四叉树在 Culling(剔除)中的作用
想象我们有大量想要渲染的模型。最朴素的做法是:
遍历所有模型 → 检查每个是否在相机视图中 → 渲染。
对于成千上万的实例,这个流程会非常缓慢——因为我们对”那些根本不可能可见的整片区域”也付出了 O(N) 的检查代价。
利用四叉树,我们可以将大列表拆成更小的列表,并跳过其中一些:


具体步骤:
- 用所有模型位置的总边界,确定四叉树需要覆盖的空间大小;
- 持续细分,直到每个子空间只包含少量模型;
- 把每个模型
Bounds.Contains检查后,分配到对应的叶节点列表; - 渲染时,从根节点开始向下检查视锥体相交:


在树的下一层,往往有一半的节点不在视野内,我们直接跳过整个分支及其所有子节点——这就是空间剔除的核心收益:用 O(log N) 替代 O(N)。
三、原型实现:基于 CPU 的四叉树实例化渲染
理论清楚后,先做一个最小原型:在 Unity 中用 Graphics.DrawMeshInstanced 批量绘制实例,并用 CPU 端四叉树/八叉树进行视锥剔除。
参考实现:实例网格基础四叉形/八叉形剔除、Drawing Thousands of Meshes with DrawMeshInstanced / Indirect in Unity
1. 生成网格与基础绘制
我们先用 Graphics.DrawMeshInstanced 这个 API 来批量绘制大量实例。该函数至少需要:
| 参数 | 说明 |
|---|---|
Mesh |
要绘制的网格 |
Submesh |
子网格编号,单网格传 0 |
Material |
必须使用支持 Instancing 的着色器 |
Matrix4x4[] |
包含每个实例 TRS(位置/旋转/缩放)的矩阵列表 |
1 | |
如果实例数设到 100,000 级别,帧率会立刻肉眼可见地下降——批处理虽然帮了忙,但顶点压力依旧巨大,而且所有实例无论是否在视野内都被绘制。这正是引入空间剔除的动机。
2. 构建 CPU 四叉树(QuadTreeNode.cs)
2.1 计算根包围盒
1 | |
2.2 递归构建子节点
四叉树只在 X/Z 轴划分(Y 轴保留全长),从父节点中心向 4 个角偏移 size/4,子节点尺寸为父节点的一半:
1 | |
从四叉树到八叉树:只需在 Y 轴也偏移一层,原本 4 个子节点变成 2×4 = 8 个,构造逻辑完全对称。当数据在垂直方向上变化剧烈(如装满立方体空间的实例),八叉树能给出更紧的剔除边界。
2.3 把矩阵分配到叶节点
1 | |
构建完成后再调一次 ClearEmpty() 修剪空叶子,保持树结构紧凑。
3. 基于摄像机的视锥体剔除
剔除流程的三步走:
- 提取视锥平面:
GeometryUtility.CalculateFrustumPlanes(Camera.main)拿到 6 个裁剪平面; - AABB-视锥相交测试:
GeometryUtility.TestPlanesAABB(planes, bounds); - 递归收集可见叶子的实例矩阵。
1 | |
主循环里只在相机变换发生变化时重算可见集合,再交给 DrawMeshInstanced:
1 | |
4. 原型成果
完整原型代码如下:
CullingInstancedDemo.cs
1 | |
QuadTreeNode.cs
1 | |
在 100,000 实例规模下,开启四叉树剔除后:
- 绘制数量:100,000 → ~34,000(视野相关)
- 帧率:33 FPS → 250+ FPS(参考数据,因机器而异)
- 顶点压力:从 89.7M 降到 33.9M
至此我们得到一个能跑、效率不错的 CPU 端原型。但当我们把目光转向真正的”大世界”时,问题来了。
四、瓶颈与进化:为什么我们需要 GPU-Driven?
1. CPU 方案的局限
我们把场景规模从”装满几万实例的立方体”放大到”10240m × 10240m 的开放世界地形”——
- 若以 8m 一个 Patch 铺满整个世界,总共需要 1280 × 1280 = 1,638,400 个地块;
- 即使引入 LOD 四叉树,CPU 端每帧仍要做:节点遍历、LOD 评估、视锥剔除、
Matrix4x4列表组装、传给DrawMeshInstanced; - 数据流向是反的:CPU 计算出实例列表 → 拷贝到 GPU 显存 → GPU 才开始绘制。每帧的 CPU↔GPU 数据搬运成为新的瓶颈;
Graphics.DrawMeshInstanced还有单批最多 1023 实例的硬限制。
更深层的问题是:地形渲染天然容易遭遇 Vertex Bound(顶点性能瓶颈)。Patch 网格密集,但视野中真正需要高精度的只有近处一小撮——CPU 没有任何”按像素细颗粒度调整 LOD”的能力。
2. 转移到 GPU 的四大核心优势
将整个剔除/LOD 管线搬到 GPU(即 GPU-Driven Terrain),可以归结为 “打破性能瓶颈”与”建立高效的渲染生态”。具体有以下四大核心优势:
- 数据流向高度契合:渲染相关的数据最终仅由 GPU 来消耗,因此直接在 GPU 上进行处理是最自然的选择,减少了 CPU↔GPU 带宽传输开销。
- 解放 CPU:转移工作负载可以直接消除 CPU 在地形顶点处理和剔除上的计算开销。
- 榨干 GPU 性能:这看似矛盾,但其实是该方案的精髓。利用 GPU 上的可用数据,可以实现更精确的 LOD 选择和最大程度的顶点剔除(Vertex Culling)。因为地形渲染极易遭遇顶点性能瓶颈(Vertex Bound),这种深度的剔除优化使得该方案不仅没有增加 GPU 的负担,反而”物超所值”。
- 系统间的协同效应:当地形信息直接驻留在 GPU 的数据结构中时,其他基于 GPU 的渲染系统(例如负责生成树木、岩石、草地等的 Compute Shader)可以直接访问并利用这些基础数据,大幅提升整体场景的渲染效率。
下面进入正题——GPU-Driven Terrain 的整体架构。
五、GPU-Driven Terrain 核心架构
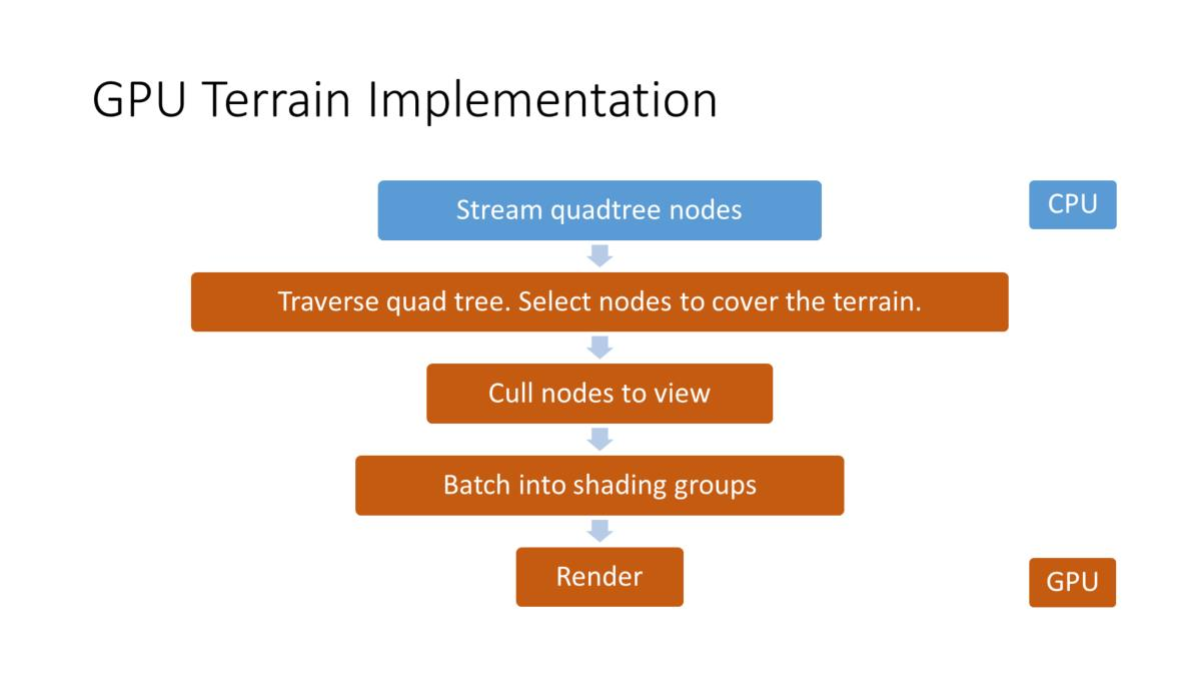
系统基于 GPU Driven + 四叉树(QuadTree)+ 实例化渲染(Instancing) 的思想构建。在整个渲染管线中,CPU 端 TerrainManager 仅负责分发 Dispatch 指令并维护 Compute Buffers,真正的视锥剔除、遮挡剔除、LOD 评估以及最终绘制数据的生成都在 GPU(Compute Shader)中完成。
1. 地形分块

可以建立以下对地形分块的概念:
World大小为 10240m × 10240mQuadTree有 6 层,从上往下分别代表LOD5 ~ LOD0- LOD 层级:LOD5 有 5×5 = 25 个节点,往下依次 ×2,直到 LOD0 有 160×160 个 Node;在最粗糙的 LOD 下,整个世界由
个大区块(Node)组成 - 单个 Node 的覆盖范围从
LOD5 ~ 0依次为[2048m, 1024m, 512m, 256m, 128m, 64m],所有 LOD 层级的节点 ID 连续编号,上限MAX_NODE_ID = 34124(等比数列求和) - 基础网格(Patch):地形被划分为多个 Patch。每个 Patch 是一个
网格的 Plane - 我们称 64m × 64m 为 Sector,即 LOD0 的 Node 大小
- 在实际渲染的时候,我们会将 Node 打散成 8×8 共 64 个 Patch 作为基础单位提交给 GPU 进行 Instance 渲染
假如不使用 LOD,用 Patch 铺满整个世界,那么
2. 数据结构
系统在 GPU 端主要维护了以下几个关键结构:
NodeDescriptor:记录节点是否被继续细分(b_divide)PatchDescriptor:描述最终需要渲染的区块属性,包括世界坐标(position)、高度区间(minMaxHeight)、当前 LOD 级别(lod)以及用于处理接缝的压缩 LOD 过渡信息(lodTransPacked)
3. 资源管理(TerrainAsset / TerrainHelper)
- MinMaxHeightMap:RG32 格式,带 Mipmap,每个 Mip 对应一个 LOD 层级的高度范围,用于 AABB 构建和节点评价的 Y 坐标
- LOD Map:每帧动态生成,R8 格式,160×160,
enableRandomWrite = true,FilterMode.Point(不需要插值) - Patch Mesh:16×16 网格、边长 8m 的平面网格,居中生成(顶点偏移
-totalSize * 0.5f),在TerrainHelper.CreateTerrainPlaneMesh中静态创建并缓存
所有 ComputeBuffer 在 Dispose 中统一释放,ShaderIDs 内部类预缓存所有属性 ID,避免每帧字符串 Hash 开销。
4. GPU 渲染管线总览
在 TerrainManager.cs 的 Update 中,每帧按顺序执行以下 4 个核心 Pass:
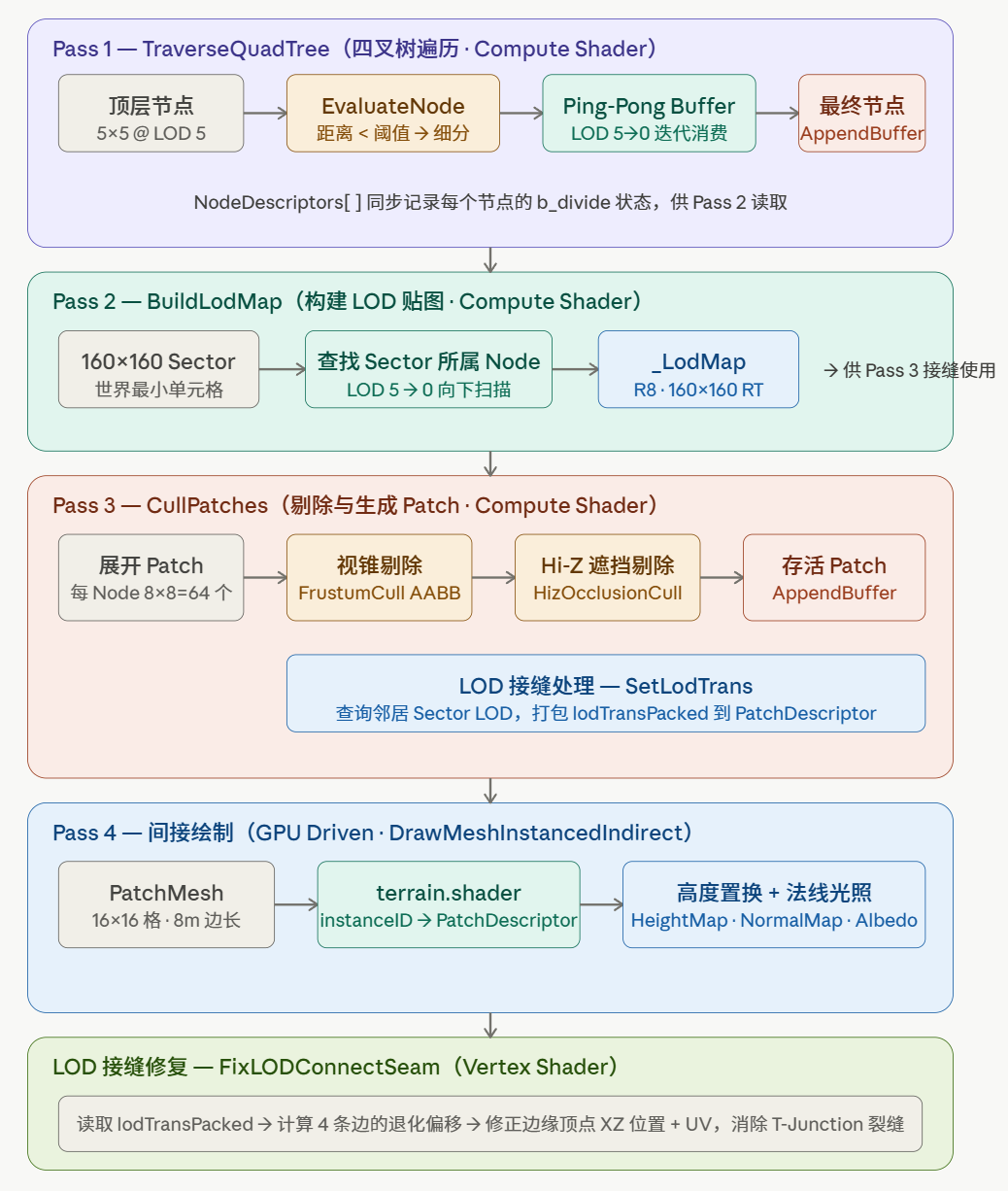
Pass 1 TraverseQuadTree(四叉树遍历)
从顶层 LOD5 的 25 个节点自顶向下遍历,对每个节点调用 EvaluateNode:计算节点中心到相机的平方距离,与 nodeSize × distanceEvaluation 的平方比较。距离足够近且 LOD > 0 则细分,将子节点(nodeIndex * 2 的四个方向)推入 ProduceBuffer;否则写入 FinalNodeList。
- Ping-Pong Buffer:每一 Pass 交换 Consume/Produce Buffer,通过
DispatchCompute(..., _indirectArgsBuffer, 0)实现 GPU 驱动的间接调度,无需 CPU 回读节点数量。 - 节点 ID 计算:使用等比数列求和公式来计算节点在显存中的全局偏移量:
,并通过位运算 (1u << (2u * m))加速计算。
Pass 2 BuildLodMap(构建 LOD 贴图)
构建地形 LOD 贴图是为了后续处理地形接缝。
- 对 160×160 的 Sector 空间(每个 Sector 是世界最小单元),从 LOD 5 向 0 遍历,找到该 Sector 所属的第一个未细分节点,将其 LOD 值写入
的 _LodMap(R8 格式 RenderTexture)。 _LodMap记录了地形上每一个基础 Sector 对应的最终 LOD 级别,方便相邻 Patch 快速查询邻居的 LOD 状态,是 Pass 3 接缝计算的依据。
Pass 3 CullPatches(剔除与生成 Patch)
这部分是 GPU Driven 性能优化的核心所在。剔除分两层:
- 视锥体剔除(Frustum Cull):对 Patch 的 AABB(利用
minMaxHeightMap获取高度范围)做六平面测试,使用 “AABB 投影半径” 方法,一次点积完成整个包围盒测试。 - Hi-Z 遮挡剔除(Hi-Z Occlusion Cull):
- 将世界空间的 AABB 投影到屏幕的 UV 和深度空间(
GetBoundsUVD)。 - 根据 AABB 在屏幕上的大小,计算出需要采样的 Hi-Z Map 对应的 Mipmap 层级。
- 采样该层级的 4 个极值像素深度,如果物体自身的最浅深度(考虑反转 Z)依然被遮挡物覆盖,则将其剔除。
- 将世界空间的 AABB 投影到屏幕的 UV 和深度空间(
LOD 过渡信息录入:对于存活的 Patch,通过采样 _LodMap 判断其上下左右四个方向的邻居 LOD 是否比自己更粗糙,将差值打包存入 lodTransPacked。随后追加进 VisiblePatches(AppendBuffer)中。
1 | |
Pass 4 DrawMeshInstancedIndirect(间接绘制)
- CPU 端无需回读(Readback),每个实例的 Vertex Shader 通过
SV_InstanceID索引_VisiblePatchList读取PatchDescriptor,完成:缩放(scale = 1 << lod)、位移(世界坐标)、高度图采样(置换顶点 Y)、法线图采样(计算简单漫反射光照)。 - 调用
Graphics.DrawMeshInstancedIndirect一次性完成所有可见地形块的绘制。
六、核心改造:GPU 上的四叉树 LOD 计算
四叉树 LOD 是整个 GPU 驱动地形中最核心、也最考验底层逻辑设计的部分。这里我们对比第三章的 CPU 树结构,凸显 GPU 化改造的关键点。
CPU vs GPU:核心思路对比
| 维度 | CPU 原型(第三章) | GPU-Driven(本章) |
|---|---|---|
| 节点存储 | 嵌套 class 对象,children 是 List<QuadTreeNode> |
一维 ComputeBuffer<NodeDescriptor>,按等比数列偏移寻址 |
| 遍历方式 | 递归 RetrieveLeaves(深度优先) |
Ping-Pong 双缓冲 + 逐层 LOD Pass(广度优先) |
| 剔除测试 | GeometryUtility.TestPlanesAABB(C# API) |
Compute Shader 中的 AABB 投影半径 + Hi-Z |
| 可见集合输出 | List<Matrix4x4> 拷贝回 CPU |
AppendBuffer 直接驻留 GPU |
| 绘制 API | Graphics.DrawMeshInstanced |
Graphics.DrawMeshInstancedIndirect(无 CPU 回读) |
| LOD 邻居查询 | 不支持 | 光栅化 _LodMap,O(1) 查询 |
1. 四叉树的空间架构定义
在进入计算之前,系统对世界进行了宏观的网格划分:
- 初始状态(最粗糙级):整个地形在最高 LOD 层级(
MAX_TERRAIN_LOD = 5)下,并不是一个单一的根节点,而是由( MAX_LOD_NODE_COUNT = 5)个大区块组成。 - 满树状态(最精细级):如果全部细分到
LOD 0,最大节点总数为个( MAX_NODE_ID = 34124)。 - 节点描述(
NodeDescriptor):显存中维护了一个结构体数组,每个节点仅包含一个b_divide字段,用于标记该节点当前帧是否被一分为四。
2. 核心运行机制:自顶向下的 Ping-Pong 迭代
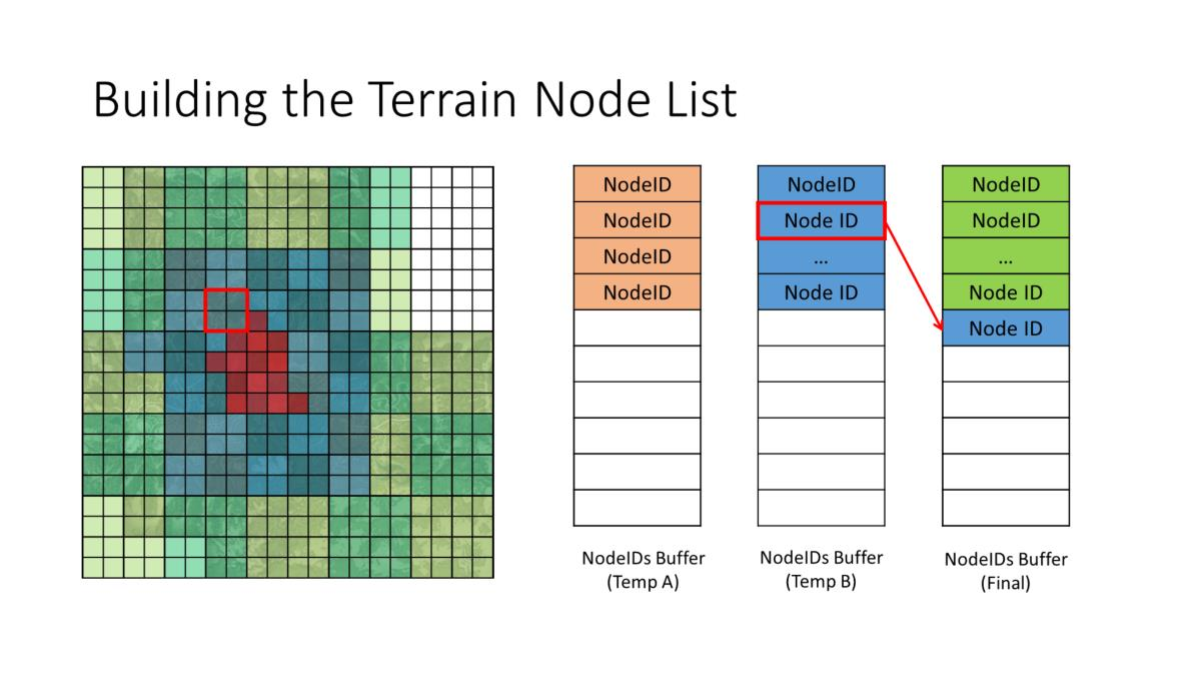
四叉树的遍历在 TraverseQuadTree Kernel 中完成,采用的是逐层降维的方式:
- 双缓冲交替(Ping-Pong Buffers):系统在 C# 端维护了两个临时 Compute Buffer(
_tempANodeListBuffer和_tempBNodeListBuffer)。 - 迭代过程:
- 循环从最粗糙的
LOD 5开始,降至LOD 0。 - 每一层循环中,GPU 从
ConsumeNodeList中取出当前层的节点进行评估。 - 如果节点需要细分,则计算出 4 个子节点的索引(乘以 2 并加上偏移
(0,0)、(1,0)、(0,1)、(1,1)),塞入ProduceNodeList中供下一层级使用,并将当前节点的b_divide设为true。 - 如果不需要细分(或已经到底),则将其塞入
AppendFinalNodeList作为最终需要渲染的节点,并将b_divide设为false。 - 下一次循环时,交换读写 Buffer(Ping-Pong 交换)。
- 循环从最粗糙的
对照 CPU 版的
RetrieveLeaves递归——递归调用栈、堆上对象、List.AddRange全没了,全部数据扁平地流过 GPU 缓冲。
1 | |
3. LOD 评价函数(EvaluateNode)
决定一个节点是否需要”分裂”的逻辑非常直接,包括:
- 与摄像机的距离
- 高度变换剧烈程度
- etc.
本项目只使用 距离与尺寸的比例关系:
评价标准:根据外部传入的评价系数 _NodeEvaluationC.x 乘以 nodeSize 得到阈值。如果距离平方小于阈值平方(即离相机足够近),则返回 true,触发细分。
1 | |
4. 显存管理优化:一维索引(GetNodeId)
四叉树本质上是层级结构,但 GPU 的 Buffer 是一维数组。为了不产生读写冲突并快速定位节点数据,代码中使用了数学公式来计算节点在 1D 数组中的偏移量:
- 等比数列求和:计算当前 LOD 距离最粗糙 LOD 细分了多少次(设为
)。因为每细分一次,节点数是上一层的 4 倍,这是一个公比为 4 的等比数列。 - 核心公式:
(其中 是初始的 )。 - 位运算加速:代码中使用了
1u << (2u * m)来极速替代的计算,极大压榨了 GPU 算力。
1 | |
5. 生成 LOD Map
四叉树遍历完成后,最终的 LOD 信息会被光栅化到一张全局的二维纹理 _LodMap 中(通过 BuildLodMap Kernel):
- 该 Pass 遍历每一个最小粒度的网格(Sector)。
- 自顶向下(从最粗糙到最精细)查询当前空间对应的四叉树节点状态。
- 一旦遇到
b_divide == false的节点,说明该处停止了细分,便将当前的 LOD 值写入_LodMap纹理并直接return。
1 | |
这张 Map 脱离了树状结构,使得后续生成 Patch 时,任意地形块都可以通过简单的 UV 采样,以
七、GPU 剔除与管线绘制
继续与 CPU 原型对照——上一章我们用 GeometryUtility.TestPlanesAABB,本章把整套剔除搬到 Compute Shader 中,并把 Graphics.DrawMeshInstanced 升级为 Graphics.DrawMeshInstancedIndirect。
1. GPU 端的视锥体剔除
不再依赖 C# 的 GeometryUtility——在 Compute Shader 中直接对 Patch 的 AABB(高度范围来自 MinMaxHeightMap)做六平面测试,使用 AABB 投影半径 方法:一次点积完成整个包围盒测试,比逐点测试快得多。
2. Hi-Z 遮挡剔除
CPU 原型完全没有遮挡剔除能力——你站在山后,山前的所有地块依旧会被绘制。GPU 端则可以做性价比极高的遮挡剔除:
- 将世界空间的 AABB 投影到屏幕的 UV 和深度空间(
GetBoundsUVD)。 - 根据 AABB 在屏幕上的大小,计算出需要采样的 Hi-Z Map 对应的 Mipmap 层级。
- 采样该层级的 4 个极值像素深度,如果物体自身的最浅深度(考虑反转 Z)依然被遮挡物覆盖,则剔除。
详细原理参见:
3. 绘制指令升级:从 DrawMeshInstanced 到 DrawMeshInstancedIndirect
| 维度 | Graphics.DrawMeshInstanced |
Graphics.DrawMeshInstancedIndirect |
|---|---|---|
| 实例上限 | 单批 1023 | 仅受显存限制 |
| 数据来源 | CPU 端 Matrix4x4[] |
GPU ComputeBuffer(_VisiblePatchList) |
| CPU 回读 | 必须(要把可见列表传过去) | 不需要(间接参数也在 GPU) |
| 适配 GPU-Driven | 不适配 | 完美适配 |
整个调用链变成:Compute Shader 把可见 Patch 直接 Append 到 _VisiblePatchList → Graphics.DrawMeshInstancedIndirect 通过间接参数缓冲一次性绘制。CPU 完全不需要知道这一帧到底要画多少个 Patch,这是与第三章 CPU 原型最本质的区别。
八、渲染细节:地形材质与 LOD 接缝修复
地形的表面渲染在 terrain.shader 中完成,当前实现比较基础。
1. 高度场采样
在顶点着色器中,根据基础顶点坐标和 _HeightMap 采样出对应的高度信息,并应用高度缩放和偏移量:
1 | |
2. LOD 接缝处理(Seam Fix)
针对相邻地形 Patch 之间由于 LOD 层级不同而产生的网格接缝问题(LOD Seam)。核心处理思路是将高精度边缘的顶点”吸附(Snap)”到低精度边缘的顶点位置上。
具体步骤(FixLODConnectSeam):
- 从
lodTransPacked解包出四条边(左/下/右/上)各自的 LOD 差值; - 用位运算批量计算退化步长:
mask = (1 << lodTrans) - 1,即模数掩码; - 判断当前顶点是否处于对应边缘(
vertexIndex.x == 0等); - 对处于边缘的顶点计算偏移量并修正 XZ 坐标和 UV,一次赋值完成。
整个算法没有 if-else 分支,全用向量乘法和掩码实现,GPU 友好。
FixLODConnectSeam
1 | |
九、结语与 Future Work
回顾全文,我们沿着”理论 → CPU 原型 → GPU 进化“的脉络,搭建出了一套完整的 GPU-Driven 地形渲染框架:
- 用四叉树空间剔除把 O(N) 的暴力遍历降到 O(log N);
- 用 Ping-Pong 缓冲把递归遍历改写成 GPU 友好的逐层迭代;
- 用
_LodMap把树状邻居查询降到 O(1); - 用 Hi-Z + 视锥双重剔除把可见集合压到最小;
- 用
DrawMeshInstancedIndirect彻底斩断 CPU 回读链路。
受限于时间关系,本项目主要跑通并复刻了 GPU-Driven 的核心基础原型(四叉树分割、视锥/Hi-Z 剔除、LOD 接缝处理等)。目前尚未包含复杂的地形材质混合系统,但在后续的迭代中,可以结合 RVT(运行时虚拟纹理)等技术,将其拼装成一个完整、工业级的地形渲染模块。
🔗 项目开源地址:
后续进阶与拓展方向(Future Work)
- 阴影剔除分离(Shadow Culling Separation)
- 问题:目前的
VisiblePatches完全依赖主相机的视锥体剔除。如果一座山坡正好在玩家身后(被剔除),但太阳光正好从玩家背后照过来,这座山就不会投射阴影到玩家视野内,导致严重的阴影穿帮(Shadow Popping)。 - 解决思路:
- 在 C# 端将 Buffer 一分为二,创建
_mainCameraVisibleBuffer和_shadowCasterVisibleBuffer。 - Dual Dispatch:
CullPatches核函数每帧 Dispatch 两次。一次传入主相机矩阵进行精准剔除;一次传入光源相机矩阵(或稍微放宽的灯光包围盒范围)进行阴影剔除。 - Shader 分离:在
terrain.shader中,主渲染 Pass 读取 Main Buffer,而ShadowCasterPass 专门读取 Shadow Buffer。
- 在 C# 端将 Buffer 一分为二,创建
- 问题:目前的
- 超大纹理与多地表混合(SVT / RVT / Texture Array)
- 问题:现阶段仅使用了一套
_AlbedoMap和_NormalMap。面对动辄 10km × 10km 的大世界,单张贴图精度远远不够(地表极其模糊);但如果将贴图切碎按材质赋予,材质球数量暴增,又会破坏 GPU Instancing 的初衷。 - 解决思路:
- 方案 A(Texture Array):将草地、泥土、岩石等多套贴图打包成一个
Texture2DArray。在 Compute Shader 生成 Patch 时,额外采样控制图,计算出该 Patch 占主导地位的地表材质 Index 存入PatchDescriptor,传给 Fragment Shader 进行动态采样与混合。 - 方案 B(RVT - Runtime Virtual Texturing):直接利用 URP 的 RVT 系统。底色可以直接烘焙在一张极低分辨率的 Global Map 上;在摄像机周围区域,利用高度图和材质权重图实时在内存中光栅化生成一张高精度 RVT,从而实现无限细节的无缝地表。
- 方案 A(Texture Array):将草地、泥土、岩石等多套贴图打包成一个
- 问题:现阶段仅使用了一套
- CPU 与 GPU 的物理碰撞同步(Physics Collision)
- 问题:地形完全由 GPU 生成,甚至在 Vertex Shader 中发生了高度位移。CPU 端的物理引擎(如
MeshCollider)对地面的真实起伏一无所知,导致角色会掉下虚空或无法行走。 - 解决思路:
- 角色贴地:放弃在 CPU 生成数百万顶点的
MeshCollider。直接在 CPU 端维护一份二维高度图数据float[,]。每次角色判定脚底高度时,在 CPU 端利用坐标换算,双线性插值采样该数组即可,速度极快。 - 复杂物理碰撞(载具/刚体):采用按需加载(Streaming) 的思路。只在玩家周围的 9 宫格(Node)范围内,利用 CPU 高度图动态生成少量低精度
MeshCollider,挂载到隐藏的 GameObject 上。随着玩家移动,这些 Collider 的顶点数据被循环复用和更新。
- 角色贴地:放弃在 CPU 生成数百万顶点的
- 问题:地形完全由 GPU 生成,甚至在 Vertex Shader 中发生了高度位移。CPU 端的物理引擎(如
-
植被与细节网格联动(GPU Foliage / Grass System)- 问题:地表有了,但缺少海量的草地和树木。传统的 CPU 种草方案 DrawCall 极高且难以和动态高度图完美贴合。
- 解决思路:
- 既然地形的高度、法线以及权重分布(
_ControlMap)都在 GPU 显存中,可以直接利用这些数据构建 GPU 驱动的植被系统。 - 新开一个 Compute Shader,根据
_ControlMap的权重(决定哪里长草、长什么草),在对应的地形 Patch 范围内随机生成数百万棵草的 TRS 矩阵。 - 在 GPU 端读取地形的真实高度调整草根的 Y 轴坐标,最后同样利用
DrawMeshInstancedIndirect一次性渲染海量植被。
- 既然地形的高度、法线以及权重分布(