
「PBR 系列」第五篇 · 次表面散射与能量补偿:从 BSSRDF 到 Kulla-Conty
核心结论:PBR 的最后两块拼图是高维次表面散射(皮肤、玉石)和单次散射的能量找回(Kulla-Conty)。前者把 4D 的 BRDF 推广到 8D 的 BSSRDF,靠扩散剖面 + Gaussian Sum 在屏幕空间或纹理空间近似;后者通过预积分 LUT 把单次散射 Cook-Torrance 丢失的能量加回,让粗糙金属在白炉测试中真正达到能量守恒。本篇收尾整个 PBR 系列。
一、半透明材质与 SSS:本质问题
半透明材质在生活中无处不在:树叶、纸、蜡烛、牛奶、布料、生物的皮肤、贝壳、玛瑙等。事实上,几乎所有非金属物体都存在一定程度的**次表面光传输(Subsurface Light Transport, SSLT)**现象 [Pharr 2010]。
入射光线被介质部分吸收(获取颜色)并经过多次散射,返回并从进入点周围的 3D 邻域处表面离开。而有时光线会完全穿过像耳朵、鼻翼这样的薄薄区域,形成透射(Transmittance)。
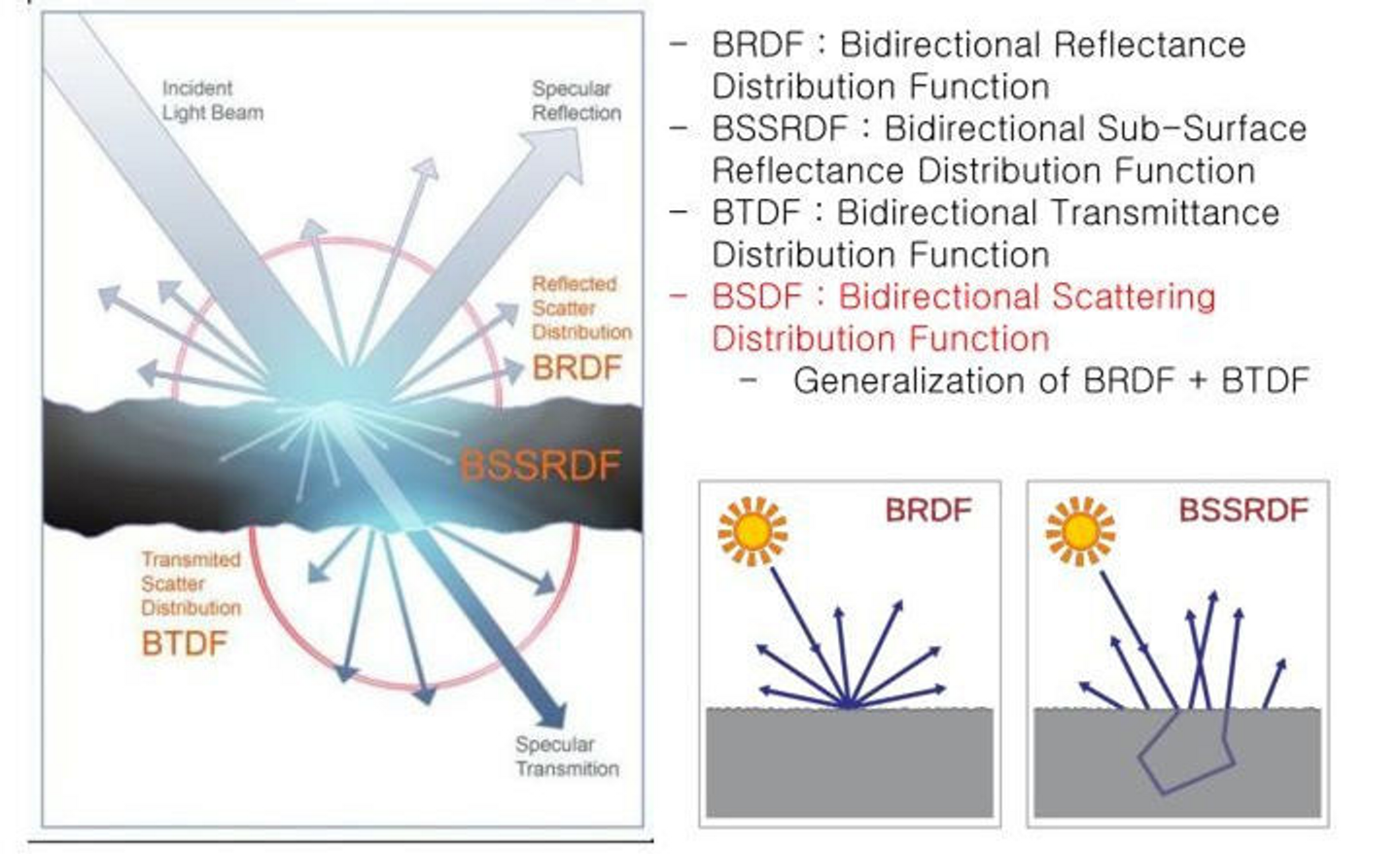
1.1 BRDF 的局限性
传统的 BRDF 模型是 BSSRDF 的一种简化。BRDF 假设光线从同一点入射和出射(同一个表面点),而 BSSRDF 可以指定不同的光线入射位置和出射的位置:
注意到积分维度从 BRDF 的 4 维(半球方向积分)跃升到 BSSRDF 的 8 维(双方向 + 双位置)。这是为什么实时 SSS 必须近似简化的根本原因。
1.2 维度对比
| 函数 | 维度 | 实时可行性 |
|---|---|---|
| BRDF | 4 | 完全可行(每像素 ≈ 50 次 ALU) |
| BSDF | 4 | 可行(透射部分需折射处理) |
| BSSRDF | 8 | 必须近似(屏幕空间或预积分) |
主流 BSSRDF 简化路径是假设各向同性散射 + 仅依赖距离 r,将 8D 函数简化为 1D 扩散剖面
其中
二、扩散剖面(Diffusion Profile)
2.1 概念
扩散剖面是描述光线如何在半透明物体中扩散和分布的函数。可以理解为:
- 一个记录次表面散射细节的”地图”;
- 一个 LUT,告诉你什么距离的像素应该被多大权重的光照影响;
- 一张”权重查找表”。
不同皮肤渲染方法,本质上就是对扩散剖面的不同近似。
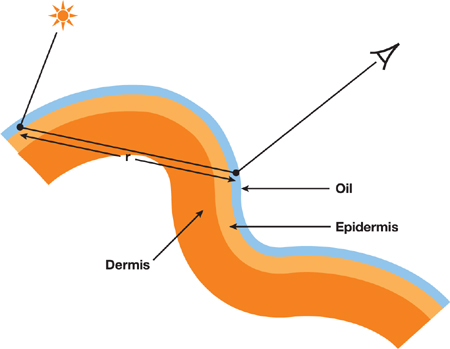
2.2 颜色相关性
扩散剖面具有很强的颜色相关性:红光比绿色和蓝色散射得更远。这是为什么耳朵和鼻翼的边缘会呈现红润感——背光时,蓝绿被吸收,只有红色穿透出来。
每种颜色都有自己的剖面,可绘制成一维曲线。三色通道独立做卷积是 Separable SSS 的基础。
2.3 描述工具
下列方法都是用于更好描述扩散剖面的策略:
- 偶极子(Dipole)方法:Jensen et al. 2001,将多重散射近似为两个虚拟点光源的辐射;
- 多极子(Multipole)方法:扩展到分层皮肤模型;
- 高斯和(Sum-of-Gaussians)方法:本节重点;
- Burley 归一化扩散:Disney 2015,工业主流。
三、Sum-of-Gaussians 近似
GPU Gems 3 Chapter 14 提出,扩散剖面在数学上类似于高斯函数
其中:
常数
3.1 高斯求和的工程优势
高斯函数有几个独特的属性,让 SSS 计算极为高效:
- 径向对称(radially symmetric):圆形对称模糊核;
- 可分离(separable):2D 卷积可拆为两次 1D(先水平后垂直),
; - 卷积自闭合:高斯卷积高斯还是高斯,
。
3.2 大理石的四高斯近似
GPU Gems 3 给出大理石中绿光散射的四高斯近似:
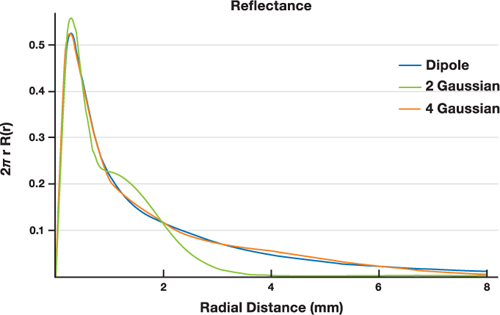
四高斯求和与精确偶极子(含 octree 结构)渲染结果不可区分。
3.3 三层皮肤模型
对人皮肤(油脂层 + 表皮 + 真皮三层),需要更复杂的高斯组合。GPU Gems 3 给出的参数:
| Variance ( |
Red | Green | Blue |
|---|---|---|---|
| 0.0064 | 0.233 | 0.455 | 0.649 |
| 0.0484 | 0.100 | 0.336 | 0.344 |
| 0.187 | 0.118 | 0.198 | 0 |
| 0.567 | 0.113 | 0.007 | 0.007 |
| 1.99 | 0.358 | 0.004 | 0 |
| 7.41 | 0.078 | 0 | 0 |
注意所有高斯权重和为 1(能量守恒)。
四、主流 SSS 方案对比
目前主流的皮肤渲染方案包含以下 4 种:
| 方案 | 类型 | 适用场景 |
|---|---|---|
| Light Warping | 经验模型,观察模拟 | 快速预览、卡通风格 |
| Pre-Integrated Skin | 预积分 LUT,倒推实现 | 手游、低端主机 |
| Spherical Gaussians | 数值解析,扩散剖面 | 中端项目、教学 |
| Separable SSS (4S) | 屏幕空间处理 | 主流 3A 方案 |
4.1 Light Warping(GPU Gems 1)
最简单的近似:将 N·L 替换为”warp 后”的 N·L,让背光的边缘也接收一些光:
或更复杂的:通过预先烘焙的 LUT 替换 N·L 项。这是最早的实时 SSS 近似,仍是低端设备的主流。
4.2 Pre-Integrated Skin(Penner 2011)
Penner 的核心 insight:SSS 的视觉效果取决于表面的曲率——曲率大的地方(鼻尖)光散射快、亮;曲率小的地方(脸颊)散射慢、暗。
将”曲率 + NoL”作为输入查 2D LUT,得到经过散射后的颜色响应:
1 | |
整个 SSS 退化为一次额外的 2D 纹理采样,是移动端皮肤渲染的事实标准。曲率可由 normal 的导数计算:
1 | |
4.3 Spherical Gaussians(球面高斯)
将光照与扩散剖面都展开为球面高斯(SG)函数的和:
球面高斯卷积球面高斯仍是球面高斯,因此可以解析地求积分。这种方法精度高、性能中等,常用于中端项目和教学场景。MJP(Matt Pettineo)的 SSS-SG 文章 是最佳学习资料。
4.4 Separable SSS(4S)
Jimenez 等人在 2009 年提出的 Screen-Space SSS,2015 年发展为 Separable SSS(4S),是当前 3A 游戏的事实标准。
核心思路:
- 在屏幕空间用一组分离高斯核近似 Burley 剖面;
- 利用高斯的可分离性,2D 卷积拆为水平/垂直两次 1D;
- 使用深度信息缩放卷积半径(远处的 SSS 范围应当更小)。
1 | |
完整流水线:
- 分离 Pass:将主光直接漫反射结果渲染到独立 RT;
- 水平模糊 Pass:水平方向高斯卷积;
- 垂直模糊 Pass:垂直方向高斯卷积;
- 合成 Pass:与镜面反射、环境光合成。
性能对比:
| 方案 | 帧时间增加(1080p) | 视觉效果 | 适用平台 |
|---|---|---|---|
| Light Warping | < 0.1 ms | 一般 | 低端移动 |
| Pre-Integrated Skin | 0.2-0.4 ms | 良好 | 中高移动 / 主机 |
| Separable SSS (4S) | 1-2 ms | 优秀 | PC / 主机 |
| Path Traced BSSRDF | 离线 | 最佳 | 影视 |
五、Translucency 近似(薄半透明)
5.1 问题:耳朵透光
实时渲染领域的半透明材质有两个主要障碍:
- 模拟光线在材质内部的散射(多次反弹);
- 在某一点接收到的光会重新发射到其他位置(递归光照问题)。
Colin Barré-Brisebois & Marc Bouchard 在 GDC 2011 提出了一个快速、消耗小的近似方案:Approximating Translucency for a Fast, Cheap and Convincing Subsurface Scattering Look。

5.2 核心思想
- 假定有反方向的光源贡献背部半透明的光照;
- 背面的透光性依据视角发生变化;
- 表面法线会对光线离开材质的角度产生偏转影响。
最终公式:
其中:
(subsurface distortion):用于改变光线穿透方向的偏移; (power):曲线的形状; (scale):整体强度。
5.3 实现参考
1 | |
_Thickness 通常由烘焙的 thickness map 提供(耳朵、鼻翼等薄区域厚度小)。这套方案在 Unity 移动端、卡通渲染、植物叶片渲染中广泛使用。
5.4 Beer-Lambert 厚介质吸收
光线穿过有色厚介质(彩色玻璃、宝石、酒水)的衰减遵循 Beer-Lambert 定律:
1 | |
这是 Disney 2015 BSDF 中 specular transmission 的核心组件。
六、能量危机:单次散射的丢失
回到第一篇的白炉测试:当 roughness = 1.0 时,纯白色金属(
6.1 微表面的”山谷”中
前面所有 BRDF 都隐含一个关键假设:光线在微表面之间只反射一次就离开。当粗糙度
Cook-Torrance 模型把这部分多次反射的能量直接丢弃,导致:
- 高粗糙度金属在白炉环境下显著偏暗;
- 不同粗糙度的金属外观能量不一致,美术调色困难;
- 对粗糙度为 1.0 的纯白金属,标准 GGX 实测能量只有理论值的 60-70%。
结论:表面越粗糙,多次散射的能量损失越大。对金属材质尤为明显,因为金属所有的反射都是高光反射,损失不能被漫反射”隐藏”。
6.2 白炉测试的严格定义
白炉测试是验证 BRDF 能量守恒的标准方法:
1 | |
期望值:对于
| roughness | 期望 | 单次散射实测 | 损失 |
|---|---|---|---|
| 0.0 | 1.0 | 1.0 | 0% |
| 0.25 | 1.0 | 0.94 | 6% |
| 0.5 | 1.0 | 0.82 | 18% |
| 0.75 | 1.0 | 0.69 | 31% |
| 1.0 | 1.0 | 0.62 | 38% |
这就是 Kulla-Conty 要解决的问题。
七、能量补偿:从 2017 LUT 到 2019 解析公式
能量补偿的研究脉络存在一个关键的时代转折。2017 年 Imageworks 提出的 Kulla-Conty 是理论与预计算的突破,而 2019 年 Fdez-Agüera 与 Turquin 等人独立提出的解析公式是实时渲染(无 LUT)的工程化突破。这两者解决的是同一个问题,但工程权衡截然不同。
7.1 问题的提出:能量去哪了
回顾第六节的白炉测试结果:
| roughness | 单次散射 GGX 输出 | 损失 |
|---|---|---|
| 0.5 | 0.82 | 18% |
| 0.75 | 0.69 | 31% |
| 1.0 | 0.62 | 38% |
光线在微表面”山谷”间多次反弹的能量被 Cook-Torrance 模型直接丢弃。粗糙度越高,丢失越严重,粗糙金属呈现暗黑色块——视觉上极不真实。
接下来的两节,按时间线展开两条工业解决方案。
7.2 2017 Kulla-Conty(Imageworks):预计算 LUT 派
论文:“Revisiting Physically Based Shading at Imageworks”, SIGGRAPH 2017
核心思想:用预计算的方式,把丢失的能量算出来存成 2D 纹理,运行时查表。
数学定义
定义方向反射率(directional albedo):
它表示给定出射角度时,BRDF 实际反射的能量比例。理想能量守恒下
定义半球平均:
补偿 BRDF 项:
最终 BRDF:
其中
工程实现
预积分阶段(仅烘焙一次):
HLSL
1 | |
运行时仅一次额外纹理采样:
1 | |
缺点
LUT 派虽然精度高,但有两个工程痛点:
- 额外纹理采样消耗带宽:移动端 PBR 已经在 BRDF LUT、Pre-filtered cubemap、Lightmap 上做了多次采样,再加一张 E_LUT 是奢侈;
- 多次采样的插值精度问题:移动端 fp16 + 双线性插值在 LUT 边界附近可能引入精度误差,反而放大能量误差;
- 存储多一份资产:64×64×R16F LUT 占 8KB,在 GPU 显存敏感的移动端是负担。
7.3 2019 解析公式派(Fdez-Agüera & Turquin):无 LUT 的工程化突破
脉络转折:2019 年前后,业界发现”为了能量补偿去查一张 LUT”在实时引擎里太奢侈了——能否用一个解析的数学公式直接拟合出丢失的能量?
关键论文:
- Carmelo J. Fdez-Agüera (2019). “A Multiple-Scattering Microfacet Model for Real-Time Image-Based Lighting”. Journal of Computer Graphics Techniques.
- Emmanuel Turquin (2019). “Practical Multiple Scattering Compensation for Microfacet Models”. Industrial Light & Magic Tech Report.
两人独立得出了等价的解析公式,不需要 LUT:
直观理解:把”无穷次散射”近似为一个等比级数求和,第一项是单次散射
关键技巧:用粗糙度直接拟合
要彻底省去 LUT,还需要让
1 | |
完整解析实现
1 | |
运行时完全不查 LUT——只是几次乘加,移动端开销几乎为 0。
7.4 三方案对比
| 方案 | 时代 | 准确度 | ALU 开销 | 带宽 | 显存 | 工业代表 |
|---|---|---|---|---|---|---|
| 单次散射 (Cook-Torrance) | 1982 | 38% 误差 (r=1) | 低 | 0 | 0 | 早期 PBR |
| 2017 Kulla-Conty LUT | 2017 | 3% 误差 | 低 | +2 次纹理采样 | +8KB | Imageworks Arnold |
| 2019 解析公式 | 2019 | 5% 误差 | 中 (+多项式) | 0 | 0 | Filament / HDRP / UE5 |
结论:由于 ALU 越来越廉价,2019 年的解析拟合方案正在成为现代实时引擎的主流选择。Filament 已彻底切换到无 LUT 路径,UE5 Substrate 也走这条路。HDRP 在不同的 lit 子模型中两种方案并存,给开发者选择空间。
对应文献查阅指引:实际查阅源码时,Filament 中的
MultiScatteringFactor、Khronos glTF Sample Renderer 中的getIBLRadianceGGX都使用 2019 解析方案;而 UE 早期版本(4.27 之前)的EnvBRDFApprox中仍可见 2017 LUT 残留。
7.5 视觉验证
应用任一方案后的白炉测试:
| roughness | 单次散射 | + 2017 LUT | + 2019 解析 | 期望 |
|---|---|---|---|---|
| 0.5 | 0.82 | 0.99 | 0.97 | 1.0 |
| 0.75 | 0.69 | 0.98 | 0.96 | 1.0 |
| 1.0 | 0.62 | 0.97 | 0.94 | 1.0 |
两种方案都把误差从 38% 压到 5% 以内,肉眼几乎不可见。LUT 派精度略高,但解析派性能优势明显。
八、SpongeCake:分层微薄片前沿(2023)
王宁北等人提出的 SpongeCake 是基于微薄片理论的分层 BSDF 模型(详细介绍见第四篇)。这里关注它在 SSS 方向的延伸。
8.1 模型核心
每层为基于微薄片(如 SGGX 微薄片,Henyey-Greenstein 等相位函数)或其他相位函数的均匀的体积散射介质。层内的体积介质可以具有任何的吸收和散射属性,且层间无反射 / 折射界面(可选底部基底除外)。
8.2 单散射层 BRDF 推导
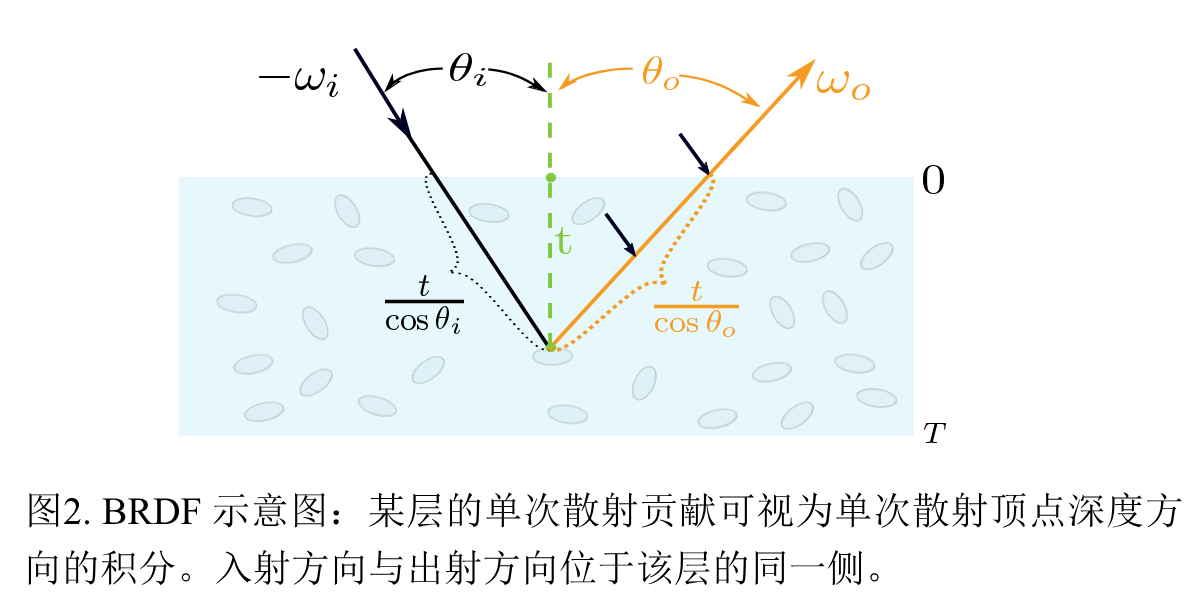
BRDF 构建:
令
积分得到:
最终匹配 NDF / G 项:
其中 G 项体现了体积衰减:
8.3 SGGX NDF
使用 SGGX 法线分布:
S 是 3×3 对称矩阵,决定了微薄片的取向分布。这使得 SpongeCake 可以同时表达表面状(surface-like)和纤维状(fiber-like)的微薄片。
8.4 工程意义
SpongeCake 是当前离线渲染最完整的 layered BSDF 模型之一,支持:
- 任意层数体积层的精确解析单散射;
- 多重散射的解析近似(通过添加修改参数的单散射 lobe + 朗伯 lobe);
- 轻量级神经网络预测参数(预训练,渲染时无需推理);
- 支持微薄片方向映射(避免传统法线映射 artifacts);
- 模拟塑料、木材、布料、植物叶片、粗糙金属、带光泽涂层木材等多种材质。
当前 SpongeCake 主要用于离线/影视渲染,但其”分层 + 微薄片”的思路已经在被实时引擎吸收。Unity HDRP 的 fabric 多层模型、UE5 的 Substrate 都在沿这个方向演进。
九、整个 PBR 系列总结
回顾整个系列的演进脉络:
CODE
1 | |
9.1 PBR 的本质回顾
经过这五篇的梳理,可以重新审视 PBR 的本质:
- 它不是某个具体公式——而是一套约束(能量守恒 + 互易性)下的近似框架;
- 它不是绝对物理——所有实时实现都是工程妥协,目标是”在性能预算内最大化视觉真实度”;
- 它不是一锤定音的标准——Charlie sheen、Kulla-Conty 补偿、SpongeCake 等扩展持续涌现;
- 它是一种思维方式——遇到新材质先问:”物理上发生了什么?这个现象有没有合理近似?我能用多少 ALU 换回多少视觉真实?”
9.2 PBR 的下一步
未来的趋势已经清晰:
- 可微渲染(Differentiable Rendering):BRDF 参数与神经网络的端到端反向传播,让材质参数可被自动学习;
- 实时路径追踪:硬件 RT 解锁 BSSRDF 的精确求解,逐步替代 SSSS / 预积分皮肤;
- 神经材质(Neural BRDF):用神经网络压缩高维 BTF(Bidirectional Texture Function)数据,替代解析 BRDF;
- 分层材质(Layered BSDF):UE5 Substrate、SpongeCake、Filament 多层 model,统一描述多层涂层、亚表面、布料绒毛;
- 几何 + 光照统一:Nanite + Lumen + Path Tracing 的整合让 PBR 跨入新阶段。
9.2.1 G-Buffer 的”参数爆炸”危机
传统延迟渲染管线依赖固定的 G-Buffer 布局:
1 | |
总共 16 字节/像素就能塞下完整 PBR 参数。但这套布局只够支撑标准 GGX——一旦材质变复杂:
| 高级材质 | 额外参数 | G-Buffer 占用 |
|---|---|---|
| Clearcoat | 第二法线 + clearcoat strength + clearcoatRoughness | +6 字节 |
| 各向异性 | 切线方向 + anisotropy | +5 字节 |
| Cloth Sheen | sheenColor + sheenRoughness | +4 字节 |
| Subsurface | profileIndex + scatterDistance | +4 字节 |
| Eye | scleraNormal + irisColor + irisDepth | +9 字节 |
简单组合 Clearcoat + Cloth + Subsurface 就需要 30+ 字节/像素,超过 1080p 16ms 帧预算下的带宽承受能力。
9.2.2 UE5 Substrate:从”传递参数”到”传递闭包”
Unreal Engine 5 的 Substrate 材质框架(之前称 Strata)正面应对这个问题,引入了**材质闭包(Material Closure)**的概念:
1 | |
核心思路:G-Buffer 不再存”BRDF 参数”,而是存”BRDF 闭包”——每个像素携带一个轻量级的”材质程序”描述符,运行时由 deferred lighting 阶段重新解释执行。
具体实现包括:
- Closure 类型枚举:DiffuseLambert、SpecularGGX、Sheen、Subsurface、ThinTranslucent 等;
- 可变长度 G-Buffer:每像素根据材质复杂度动态决定占用多少 bytes(常见材质 16 字节,高级材质 32-64 字节);
- 栈式 BSDF 评估:lighting pass 按 closure 序列依次累加贡献,自动处理多层材质的能量分配;
- 统一 IBL 管线:每种 closure 类型都注册了对应的 IBL 评估函数。
这种范式转换的好处:
- 美术可以任意组合 BSDF lobe——例如”金属底层 + 各向异性 sheen + 半透 clearcoat”,不需要工程预先定义 shader variant;
- G-Buffer 带宽随场景需求动态调整,简单材质场景仍享受 16 字节快路径;
- 与 Lumen / Path Tracing 的统一性:路径追踪器只需理解 closure,无需为每种材质类型写特化代码。
类似的理念在 OpenColorIO、MaterialX、Standard Surface 等行业标准中都能看到——未来的 PBR 不再是”一个 BRDF 公式”,而是”一组可组合的 BSDF lobe + 统一闭包描述”。
9.2.3 实时引擎的下一个十年
回看 PBR 这四十年,从渲染方程到 Substrate,主线其实只有一个:让光的行为既物理可信,又能在 GPU 上廉价地求值。
下一个十年的主导力量很可能来自三个方向的合流:
- 专用硬件:RT Core / Tensor Core 让以前不可能的算法(Path Tracing、Neural BRDF)变得可行;
- 统一描述:MaterialX、glTF KHR_materials_*、Substrate 让材质资产真正跨引擎;
- 混合管线:栅格化 + RT + 光追 + 神经渲染共存,按场景预算自动选择。
但无论范式如何变化,本系列梳理的”渲染方程 → Cook-Torrance → Disney → 工程化 → 扩展模型”这条主线,仍将是理解未来一切渲染技术的元语言。
十、调试与验证总结
回顾各篇出现的所有调试方法,形成最终 checklist:
10.1 数学正确性
- 白炉测试:恒定 1.0 环境光下纯白金属(
)应当输出 1.0;偏差大于 5% → 检查 D / V / F 实现; - 互易性检查:交换
,BRDF 值应不变; - NoL 边界测试:当 NoL → 0 时无奇异值(V 项中 max(NoL, 1e-5) 是常见 trick)。
10.2 视觉一致性
- 粗糙度梯度球阵:0.0 → 1.0 滑动应平滑过渡;
- 金属/电介质对比:相同 BaseColor 的 metallic = 0/1 球应有显著差异;
- 跨光照对照:白色摄影棚 vs 黄昏 HDRI vs 正午 HDRI——同一资产应保持质感一致。
10.3 工程鲁棒性
- fp16 溢出:
等大幂次计算需 max(… , 0.0078125) 防下溢; - 边界 normalize:normalize(0) 在某些 GPU 返回 NaN,加 1e-5 偏置;
- 重要性采样收敛:IBL 与 Kulla-Conty LUT 烘焙需要至少 1024 样本,否则烘焙 LUT 自身就是噪声源。
十一、工程调试
SSS 屏幕空间渗色
最常见的 SSSS bug:远处的物体边缘出现”光晕”——SSS 卷积把远处不相关的像素拉进来了。原因是 separable kernel 没按深度缩放。
1 | |
Pre-Integrated Skin 黑边
如果皮肤在曲率高的地方(如鼻翼内侧)出现”黑色阴影线”,是因为 LUT 只覆盖了 NoL ∈ [-1, 1],但你给了 clamp(NoL, 0, 1) 导致背光面查不到合理值。修复:
1 | |
Translucency 厚度贴图过薄
GDC 2011 Translucency 用 _Thickness 贴图控制透光强度。常见 bug:耳朵位置厚度贴图烘焙得过薄(接近 0),导致背光时耳朵反而完全不透光——这与直觉相反。
正确的做法:在 Maya/Blender 用 AO 反向烘焙得到 thickness(取反,深处=厚,凹处=薄)。
Kulla-Conty 解析公式的负值
2019 解析公式中 1.0 - F_avg * (1.0 - Eavg) 在 metallic = 1.0 且 roughness 极高时可能接近 0,分母过小:
1 | |
加 max(..., 1e-3) 防止能量补偿失控。
Beer-Lambert 在 HDR 下的溢出
1 | |
如果 _AbsorptionCoeff 是负数(美术误填),exp() 会指数爆炸成 INF。烘焙阶段或材质 inspector 应做参数 clamp。
参考文献
SSS / 透射
- Pharr, M. & Humphreys, G. (2010). Physically Based Rendering: From Theory to Implementation. Morgan Kaufmann.
- Jensen, H. W. et al. (2001). A Practical Model for Subsurface Light Transport. SIGGRAPH.
- d’Eon, E. & Luebke, D. (2007). Advanced Techniques for Realistic Real-Time Skin Rendering. GPU Gems 3, Chapter 14.
- Penner, E. & Borshukov, G. (2011). Pre-Integrated Skin Shading. SIGGRAPH Advances Course.
- Jimenez, J. et al. (2009). Screen-Space Perceptual Rendering of Human Skin. ACM TOG.
- Jimenez, J. et al. (2015). Separable Subsurface Scattering. CGF.
- Burley, B. (2015). Extending the Disney BRDF to a BSDF with Integrated Subsurface Scattering. SIGGRAPH Course.
- Barré-Brisebois, C. & Bouchard, M. (2011). Approximating Translucency for a Fast, Cheap and Convincing Subsurface Scattering Look. GDC.
- Chapter 16. Real-Time Approximations to Subsurface Scattering | NVIDIA GPU Gems.
- 体渲染探秘(五)次表面散射 | 知乎.
能量补偿
- Kulla, C. & Conty, A. (2017). Revisiting Physically Based Shading at Imageworks. SIGGRAPH Course.
- Heitz, E. et al. (2016). Multiple-Scattering Microfacet BSDFs with the Smith Model. SIGGRAPH.
- Fdez-Agüera, C. J. (2019). A Multiple-Scattering Microfacet Model for Real-Time Image-Based Lighting. JCGT.
- Turquin, E. (2019). Practical Multiple Scattering Compensation for Microfacet Models. Industrial Light & Magic Tech Report.
前沿
- Wang, B. et al. (2023). SpongeCake: A Layered Microflake Surface Appearance Model. SIGGRAPH.
- Epic Games (2023). Substrate Materials in Unreal Engine 5. Unreal Documentation.
- QianMo. PBR-White-Paper. GitHub.
系列结语
至此,PBR 系列五篇全部完结。从 1986 年 Kajiya 一行渲染方程,到 2023 年 SpongeCake 的神经网络分层 BSDF,整整 37 年的渲染演化被压缩进这五篇文章里。
如果你只能从这个系列带走一句话,那应该是:
PBR 不是关于”完全模拟物理”,而是关于”在工程约束下让每一个近似都有物理理由”。
这也是为什么所有讨论都需要在三个层面同时进行:物理动机、数学形式、引擎落地。脱离任何一个层面,PBR 都会变成”调参玄学”。
—— 完。